Porto Seguro – Safe Driver Prediction
Técnicas de Aprendizagem Supervisionada para Sinistros
Nesse projeto de ciência de dados, a proposta é resolver o problema proposto pela empresa Porto Seguro. Precisamos ter a previsão se um motorista registrará uma reclamação de seguro no próximo ano.
Para o desenvolvimento desse projeto será utilizado o framework CRISP-DM, onde seguiremos suas etapas, essa metodologia irá auxiliar na organização e clareza.
Além disso será feito um comparativo na etapa de Feature Selection entre os métodos Feature Importance e o RFE (Recursive Feature Elimination) para falar da importância da seleção de variáveis e como ela pode influenciar no resultado final.
Nesse projeto tem recursos como:
- CRISP-DM
- Python
- Feature Engineer
- Feature Selection (Feature Importance e RFE)
- Machine Learning
- Hiperparâmetros
- Modelo Baseline
Índice
- Código do Porto Seguro – Safe Driver Prediction
- Case com a Necessidade do Projeto
- A solução para o Negócio
- O que é um modelo de classificação?
- O que é Framework CRISP-DM
- Projeto Porto Seguro usando o CRISP-DM
- Comparando as Métricas de RFE e Feature Importance
- Comparação de Resultados
Código do Porto Seguro – Safe Driver Prediction
No link abaixo você pode ter acesso ao código do projeto completo com a resolução do problema.
Tomei o cuidado de deixar o código todo comentado com as devidas explicações e orientações necessárias para reprodução.
É recomendado ler todo o conteúdo para ver a associação ao CRISP-DM e entender como o problema foi resolvido e o porquê das soluções adotadas.
Eu deixei os arquivos numerados onde representam a ordem que foram executados, isso é apenas para fins didáticos e ilustração do processo.
Link para Projeto no GitHub: https://github.com/lacostamkt/pcd_porto_seguro_safe_driver_prediction
Etapas:
- Preparação dos Dados
- Feature Engineer
- Modelo Baseline
- Feature Selection (Feature Importance e RFE)
- Modelos desenvolvidos
- Escoragem
Case com a Necessidade do Projeto
O case da Porto Seguro foi retirado diretamente do site do projeto onde tem as informações e orientações, assim como os dados a serem utilizados para criação do modelo, o link está no final dessa seção.
Sobre o case:
Nada estraga a emoção de comprar um carro novo mais rapidamente do que ver sua nova fatura de seguro.
A dor é ainda mais dolorosa quando você sabe que é um bom motorista. Não parece justo que você tenha que pagar tanto se tiver sido cauteloso na estrada durante anos.
A Porto Seguro, uma das maiores seguradoras de automóveis e residências do Brasil, concorda plenamente. Imprecisões nas previsões de sinistros das seguradoras de automóveis aumentam o custo do seguro para bons motoristas e reduzem o preço dos maus motoristas.
Pensando nisso, o desafio é construir um modelo que preveja a probabilidade de um motorista iniciar uma reclamação de seguro de automóvel no próximo ano.
Embora a Porto Seguro tenha usado aprendizado de máquina nos últimos 20 anos, eles estão recorrendo à comunidade de aprendizado de máquina do Kaggle para explorar métodos novos e mais poderosos.
Uma previsão mais precisa permitir-lhes-á adaptar ainda mais os seus preços e, esperamos, tornar a cobertura do seguro automóvel mais acessível a mais condutores.
Fonte: https://www.kaggle.com/competitions/porto-seguro-safe-driver-prediction/data
A solução para o Negócio
Diante do problema da Porto Seguro onde era necessário prever se um motorista registraria uma reclamação de seguro (sinistro) no próximo ano.
Foi utilizado técnicas de aprendizagem supervisionada para criar modelos de classificação para checar a gravidade de um sinistro com base nos dados disponibilizados.
Nesse projeto para se obter o melhor resultado foi criado primeiro o modelo baseline para se ter métricas como base, e depois testados diversos modelos com base em dois métodos de seleção de variáveis, assim teríamos mais métricas para a tomada de decisão.
A utilização do CRISP-DM auxiliou no desenvolvimento do projeto e de todas as etapas.
E com as métricas de vários modelos foi possível escolher a que tinha os melhores resultados nessa etapa e assim fazer novas melhorias através dos hiperparâmetros.
O que é um modelo de classificação?
Um modelo de classificação é um tipo de algoritmo de aprendizado de máquina que atribui (faz a previsão) a cada dado de entrada uma categoria ou classe predefinida.
Em outras palavras, ele prediz a qual grupo um determinado item pertence, com base em suas características e padrões observados em dados de treinamento.
Imagine um modelo de classificação que recebe clientes como entrada e os classifica como “bom pagador” ou “mau pagador”. Esse exemplo pode ser visto nesse projeto de Análise de Crédito se quiser entender mais sobre o assunto.{link}
Como funciona um modelo de classificação
- Treinamento: O modelo é treinado com um conjunto de dados rotulados, onde cada item já possui a categoria correta. O modelo aprende a identificar as características que distinguem as diferentes classes.
- Previsão: Para novos dados, o modelo analisa as características e usa o que aprendeu no treinamento para prever a qual categoria eles pertencem.
Alguns Tipos de modelos de classificação:
- Regressão logística: Um método clássico para classificação binária (por exemplo, spam ou não spam, bom ou mau).
- Árvores de decisão: Usam regras simples para dividir os dados em diferentes classes.
- Redes neurais artificiais: Modelos complexos que podem aprender padrões não lineares nos dados.
Aplicações de modelo de classificação:
Nesse projeto de ciência de dados, a proposta é prever se um motorista registrará uma reclamação de seguro (sinistro) no próximo ano. Ou seja se ele fará ou não um sinistro.
Mas existem muitas outras aplicações em áreas diferentes como:
- Detecção de spam
- Análise de sentimento
- Reconhecimento de imagem
- Diagnóstico médico
Vantagens dos modelos de classificação
- Precisão: Podem ser altamente precisos na classificação de dados, especialmente quando treinados com conjuntos de dados grandes e de alta qualidade.
- Automação: Permitem automatizar tarefas de categorização e classificação, economizando tempo e esforço humano.
- Escalabilidade: Podem lidar com grandes volumes de dados com eficiência.
- Interpretabilidade: Alguns modelos, como regressão logística, são mais fáceis de interpretar do que outros, permitindo entender melhor as razões por trás das classificações.
Desafios dos modelos de classificação
- Viés: Se os dados de treinamento forem tendenciosos, o modelo também pode ser tendencioso em suas classificações.
- Dados de treinamento: É necessário um conjunto de dados de treinamento rotulado e de alta qualidade para treinar um modelo eficaz. Por isso é muito importante a fase de preparação dos dados e seleção de variáveis.
- Superajuste: O modelo pode se adaptar demais aos dados de treinamento e não generalizar bem para novos dados e assim sofrer com o overfitting.
- Explicabilidade: Alguns modelos complexos, como redes neurais artificiais, podem ser difíceis de interpretar, tornando difícil entender por que fizeram uma determinada classificação.
Resumindo, os modelos de classificação são excelentes ferramentas para categorizar e classificar dados em diferentes classes ou categorias. Eles podem ser utilizados nas mais variadas áreas.
Nesse projeto foram utilizados os seguintes modelos de classificação:
- Random Forest
- Gradient Boosting
- Decision Tree
- Logistic Regression
- LightGBM
O que é Framework CRISP-DM
Entender o que é o CRISP-DM é fundamental para seguirmos com esse projeto, já que a metodologia será utilizado para orientar nosso projeto de ciência de dados.
O CRISP-DM através de um conjunto de boas práticas, ajuda a fornecer organização e clareza no desenvolvimento de projetos da área de dados, facilitando durante o decorrer do trabalho.
Etapas do CRISP-DM:
- Entendimento do Negócio: É entender qual problema de negócio precisa ser resolvido.
- Entendimento dos Dados: Entender todo o processo envolvido na coleta, exploração e mineração dos dados e também sobre as variáveis.
- Preparação dos Dados: Etapa onde é realizado todo o tratamento dos dados (ajuste, agrupamento, padronização, normalização, etc.)
- Modelagem: Seleção de variáveis, treinamento do modelo e otimização de hiperparâmetros se necessário.
- Avaliação: Verifica se a solução desenvolvida resolve o problema de negócio identificado no início do projeto.
- Implantação: Etapa para implantar a solução desenvolvida de maneira que possa começar a gerar resultados para o cliente.
Projeto Porto Seguro usando o CRISP-DM
A partir daqui poderá ver as etapas do projeto relacionadas ao CRISP-DM e acompanhar todo o desenvolvimento e organização, até a solução proposta.
Então veja todas as etapas do projeto com toda a explicação do código gerado e o resultado obtido.
Entendimento do Negócio
Nessa etapa compreendemos os objetivos do projeto e as suas necessidades, olhando para o contexto do problema que precisa ser solucionado.
E pensando no case que temos da Porto Seguro:
Nada estraga a emoção de comprar um carro novo mais rapidamente do que ver sua nova fatura de seguro. A dor é ainda mais dolorosa quando você sabe que é um bom motorista. Não parece justo que você tenha que pagar tanto se tiver sido cauteloso na estrada durante anos.
A Porto Seguro, uma das maiores seguradoras de automóveis e residências do Brasil, concorda plenamente. Imprecisões nas previsões de sinistros das seguradoras de automóveis aumentam o custo do seguro para bons motoristas e reduzem o preço dos maus motoristas.
Nesta competição, você é desafiado a construir um modelo que preveja a probabilidade de um motorista iniciar uma reclamação de seguro automóvel (sinistro) no próximo ano.
Embora a Porto Seguro tenha usado aprendizado de máquina nos últimos 20 anos, eles querem explorar métodos novos e mais poderosos.
Uma previsão mais precisa permitir-lhes-á adaptar ainda mais os seus preços e, esperamos, tornar a cobertura do seguro automóvel mais acessível a mais condutores.
Objetivos do Projeto:
- Reduzir as imprecisões nas previsões de sinistros que geram o aumento de custo do seguro.
- Criação de modelo que preveja a probabilidade de um motorista iniciar uma reclamação no próximo ano.
- Identificar e explorar métodos novos e mais poderosos que possam vir a ser utilizados.
- Melhorar a previsão para que possam ter preços mais assertivos.
Critério de avaliação para o sucesso do projeto:
Como métrica de pontuação, as submissões serão avaliadas usando o Coeficiente Gini Normalizado.
Essa métrica foi definida no case do projeto pela Porto Seguro.
Entendimento dos Dados

Essa etapa é para entender o processo envolvido na coleta de dados que serão utilizados futuramente pelo modelo.
Onde é feita a exploração e mineração dos dados que temos para desenvolver a solução. Fase importante para entender sobre as variáveis disponíveis.
Se serão dados internos ou externos, como obteremos os dados para utilizar.
No caso do projeto da Porto Seguro todas as informações e dados utilizados para criação do modelo já foram disponibilizados no Kaggle.
Descrição do conjunto de dados
O objetivo é que seja possível prever a probabilidade de um titular de uma apólice de seguro automóvel registrar uma reclamação.
Para esse projeto não foi fornecido o Metadados ou dicionário de dados, mas sim algumas orientações.

Nos dados de treinamento e teste, os recursos que pertencem a agrupamentos semelhantes são marcados como tal nos nomes dos recursos (por exemplo, ind, reg, car, calc).
Além disso, os nomes dos recursos incluem o sufixo bin para indicar recursos binários e cat para indicar recursos categóricos.
É possível perceber também que todos os dados são do tipo numérico.
Os recursos sem essas designações são contínuos ou ordinais.
Valores de -1 indicam que o recurso estava faltando na observação (Nulo).
A coluna TARGET significa se uma reclamação foi ou não apresentada para aquele segurado. Ou seja, se teve ou não sinistro para o segurado.
Descrições de arquivos:
train.csv: Contém os dados de treinamento, onde cada linha corresponde a um segurado e as colunas de destino significam que uma reclamação foi registrada.
test.csv: Contém os dados de teste. Essa base não possui o TARGET e será utilizado para gerar o arquivo sub_mission com o resultado para avaliação.
sample_submission.csv: é um arquivo de envio que mostra o formato correto.
Por se tratar de uma competição não temos acesso ao público ou informações adicionais que possam auxiliar mais na construção, tendo apenas que trabalhar com o que foi passado (que é mais do que o suficiente) para construção do modelo.
O desafio é fazer uma boa seleção de variáveis mesmo sem ter tantas informações além do que foi fornecido.
Preparação dos Dados
Etapa de extrema importância onde é realizado o tratamento dos dados (ajuste nos tipos de variáveis, agrupamento de bases, padronização, normalização, ajustes, etc.), tudo para deixarmos os dados prontos para serem utilizados pela fase de Feature Selection e Modelagem.
Nessa etapa do CRISP-DM foi utilizado técnicas para preparar os dados com base no que foi visto no entendimento dos dados:
- Geração dos Metadados da ABT (Tabela Analítica de Modelagem)
- Tratamento de Nulos (missing)
- Exclusão de variáveis com mais de X% de nulos
- Tratamento de categóricas de alta cardinalidade (LabelEncoder)
- Tratamento de categóricas de baixa cardinalidade (OneHotEncoder)
- Aplicação de normalização em toda tabela de modelagem (ABT)
- Geração dos artefatos para implantação do dataprep realizado
- Gerar as bases para fase de feature selection
É muito importante ficar atento aos sufixos das variáveis (explicado na etapa anterior) para poder aplicar as devidas técnicas corretamente.
Detalhes sobre o processo de preparação dos dados:
No caso do projeto da Porto Seguro tinha apenas uma base de treino (Linhas: 595212, Colunas: 59) e uma de teste (Linhas: 892816, Colunas: 58) para ser utilizado.
A base de teste ficou reservada para uso na escoragem. Então foi trabalhado apenas a de treino.
– Train
Código fonte: https://github.com/lacostamkt/pcd_porto_seguro_safe_driver_prediction/blob/main/01_porto_seguro_dataprep.ipynb
Primeiramente foi preparado o ambiente que no caso está sendo utilizado o Google Colab. Onde foi definido o local dos arquivos e em seguida foi feito o importe das bibliotecas necessárias para essa etapa de preparação dos dados.
Nessa primeira parte foi feita a leitura dos dados de treino e checado o volume e a quantidade de colunas.
Também foi gerado uma amostra dos dados da base de treino devido a quantidade de dados e por possuir uma capacidade limitada de processamento, isso para que o trabalho pudesse ser realizado.
E depois foi feito a checagem da base de teste.
Fiz a separação dos dados para realização do cross-validation com valores (60% / 40%)
Feito isso é hora de tratar os dados
– Primeiro o tratamento de -1 para missing (nulos)
Seguindo as orientações da etapa de entendimento do negócio e orientações, os valores -1 indicam recurso que estava faltando.
Então para realizar o tratamento foi feito uma cópia do dataframe e feito o replace de -1 por nan (nulo).
A partir disso temos um novo dataframe com os valores nulos realmente representados.
– Criação do metados
Com isso foi gerado o metadados do dataframe para poder ser analisado. Essas informações ajudarão na tomada de decisão do que será feito com as variáveis.
{imagem metadados}
– Exclusão de variáveis com alta quantidade de nulos
- Com base no metadados gerado, foi possível ver que a variável ps_car_03_cat do tipo Explicativa possui 69.12% de nulos.
- Com base nessa informação foi definido um corte onde variáveis acima de 68% de nulos serão excluídas. Esse valor sempre pode ser analisar e realizar testes para ver como se comporta o resultado final.
Toda modificação realizada nas bases é registrada e salva para que possa ser reaplicada no test. Ou seja é criado uma lista com as variáveis a serem removidas.
Depois desse processo é criado um novo dataframe sem as variáveis removidas.
Sempre fazendo o acompanhamento dos dados com o .shape para saber se não foi feito algum procedimento errado.
Feito isso é salvo a lista de variáveis excluídas em formato .pkl para implantação no futuro.
– Tratamento de Nulos (Missing)
No tratamento de nulos na tabela de treino foi feito a imputação das variáveis categóricas e numéricas:
- Variáveis Categóricas: imputação para o valor “MISS_VERIFICAR”
- Variáveis Numéricas: imputação do valor da média
- Atenção: sempre ficar atento a outliers e checar a base, dependendo do problema a ser solucionado é interessante testar com a imputação da mediana
Após o procedimento é gerado um novo dataframe e feita a visualização para checagem.
É feito salvo a lista de variáveis e o valor médio imputado nos nulos em um arquivo .pkl para implantação. Essa rotina é comum sempre que desejar replicar o que foi feito.
Foi feito o carregamento do arquivo salvo com as informações. E gerado uma visualização para ver como ficou. Todo o detalhamento é para fins didáticos.
– Implantação na base de test
Todo o procedimento realizado acima agora é aplicado na base de test com a lista de variáveis carregada:
- Substitui valor -1 por nulos em todas as variáveis
- Separa as variáveis numéricas e preenche com a média salva da lista os valores nulos (utilizando assim o mesmo valor de treino)
- Separa as variáveis categóricas e preenche com “MISS_VERIFICAR”
- Retorna o dataframe atualizado com os valores imputados
- Checagem do volume de linhas e colunas
Tratamento de variáveis categóricas de alta cardinalidade
Para essa etapa foi utilizado o LabelEncoder.
Importante:
A base de dados fornecida pela Porto Seguro aparentemente já teve a técnica de LabelEncoder ou outra aplicada. No caso não existe nenhuma variável do tipo object ou com conteúdo texto para ser aplicado e já se encontram com os valores preenchidos.
Transformação
Foi feito a seleção das variáveis que precisam ser aplicado o LabelEncoder.
Foi definido um valor de cutoff onde as variáveis que tiverem cardinalidade maior e também forem do tipo object (no caso definimos o sufixo _cat com base na regra da Porto).
Após separar a lista das colunas tanto do dataframe treino e da lista variáveis para aplicação do labelencoder
Foi feita a transformação e ao final gerado o arquivo .pkl com as informações.
A transformação foi aplicada na base Treino:
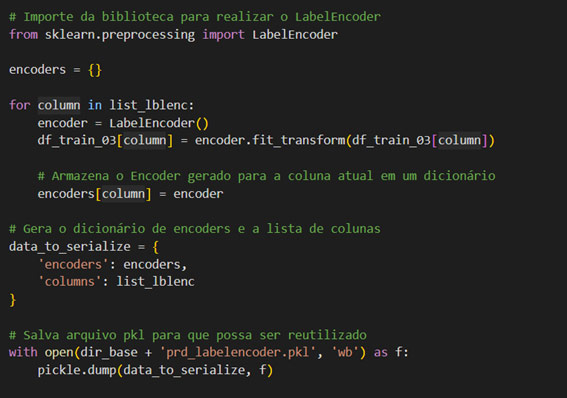
Carrega as informações e aplica as mesmas transformações na base de test.
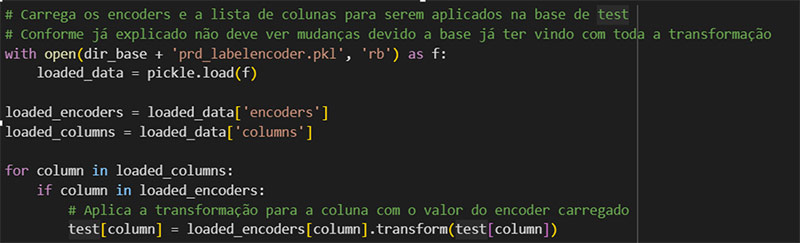
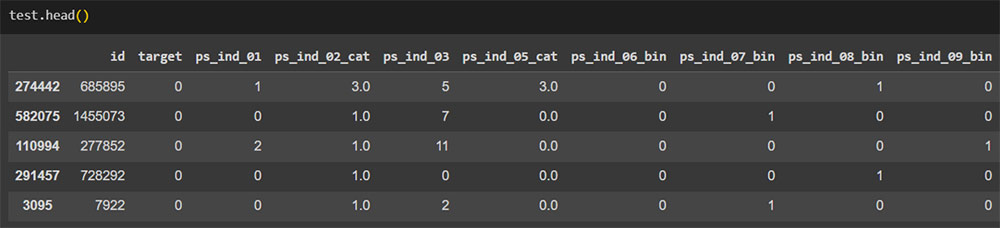
Visualização dos dados com o LabelEncoder aplicado.

Tratamento de variáveis categóricas de baixa cardinalidade
Para essa etapa foi aplicado OneHotEncoder.
Assim como no LabelEncoder, essa técnica transforma os dados em numéricos para que os algoritmos possam interpretar com maior facilidade.
Foi definido o cutoff para 2, onde apenas as variáveis com cardinalidade abaixo e igual a esse valor passariam pelo processo de OneHotEncoder.
Feito isso foi selecionado a lista de variáveis conforme os parâmetros passados.
Uma vez instanciado para uso o OneHotEncoder foi aplicado na lista de colunas que precisavam da transformação.
Com isso foi gerado um novo dataframe somente com os dados transformados.
Depois disso foi concatenado o dataframe de treino com o encodado (transformado) e removidas as colunas que sofreram o encoder (já estavam sendo representadas de maneira diferente com o OneHotEncoder) de forma binária.
Foi salva a lista de colunas em um arquivo pkl para implantação.
O mesmo procedimento foi aplicado a base de test seguindo a mesma técnica anterior de carregar a lista de colunas e encoder para aplicar.
Aplicação da Normalização a toda tabela de modelagem tratada até o momento
Esse é o processo de ajustar os valores das variáveis em um conjunto de dados para uma escala comum ou padrão.
É feito isso para garantir que todas as variáveis tenham uma influência semelhante ao modelo de aprendizado de máquina, evitando que variáveis com escalas muito diferentes dominem e influenciem todo o processo de treinamento.
A normalização é crucial antes de usar técnicas de modelagem, pois ajuda os algoritmos de aprendizado de máquina a convergirem melhor, tornando o modelo mais eficiente.
Como parte do processo de normalização é necessário remover as colunas que não devem ser normalizadas como ID e Target.
Essas colunas são reservadas para serem utilizadas novamente ao final.
Pode-se utilizar os metadados gerado para separar a lista de colunas para normalização.
Utilizei a StandardScaler da biblioteca sklearn para aplicar a normalização no dataframe.
E ao final temos um novo dataframe com os dados normalizados.
E como em todas as etapas é salvo o arquivo .pkl para implantação da normalização.
O mesmo processo da normalização é aplicado na base de teste para que as bases estejam preparadas para serem utilizadas e mantenham o padrão.
Dataprep final
Uma vez tratados todos os dados e feita todas as transformações, é pego o dataframe com as mudanças e fazemos o merge com as colunas removidas ID e Target para que nossa abt esteja completa.
Sempre aplicando o processo no Treino e no Teste.
Salvar as tabelas para próxima etapa
Feito isso é hora de salvar os dados após toda preparação, esses dados serão utilizados para criação do modelo baseline e em seguida para o Feature Selection.
Modelagem
Dando início a etapa de modelagem onde será realizado o treinamento do modelo e otimizações. Para essa serão realizados os seguintes passos:
- Criação do Modelo Baseline
- Seleção de Variáveis
- Método Feature Importance
- Método RFE
- Treinamento dos Modelos
A principal métrica a ser observada é o Gini Normalizado conforme orientação do case. Mas podemos acompanhar também pelas Acurácia, Precisão, Recall, Gini, KS e ROC-AUC.
Criação do Modelo Baseline
Antes de partir para o modelo principal e para a seleção de variáveis foi criado o modelo baseline para testar com a ABT gerada na etapa anterior, ele é o modelo mais simples possível e as métricas geradas servem de referência para o que será feito.
O modelo principal deverá ter performance melhor que o baseline, já que ele utilizará as melhores variáveis selecionadas. Caso isso não ocorra pode ser feito uma verificação para saber o que pode estar acontecendo.
Detalhes da construção do Modelo Baseline:
Código Fonte: https://github.com/lacostamkt/pcd_porto_seguro_safe_driver_prediction/blob/main/02_porto_seguro_modelo_baseline.ipynb
Como primeira parte do modelo baseline é feita a configuração do ambiente com instalação dos requisitos e importe das bibliotecas que serão utilizadas.
Depois é feita a leitura dos dados tanto de treino como teste para serem utilizados pelo modelo.
Fiz uma checagem das colunas.
Para os dados de treino foi separado o target dos demais dados de treino.
E em seguida realizado o Split da base para que pudesse ser feito o treino. Onde foram utilizados os seguintes modelos:
- DecisionTreeClassifier
- LogisticRegression
- GradientBoostingClassifier
- XGBClassifier
- LGBMClassifier
Aplicado o treino base temos as seguintes métricas:
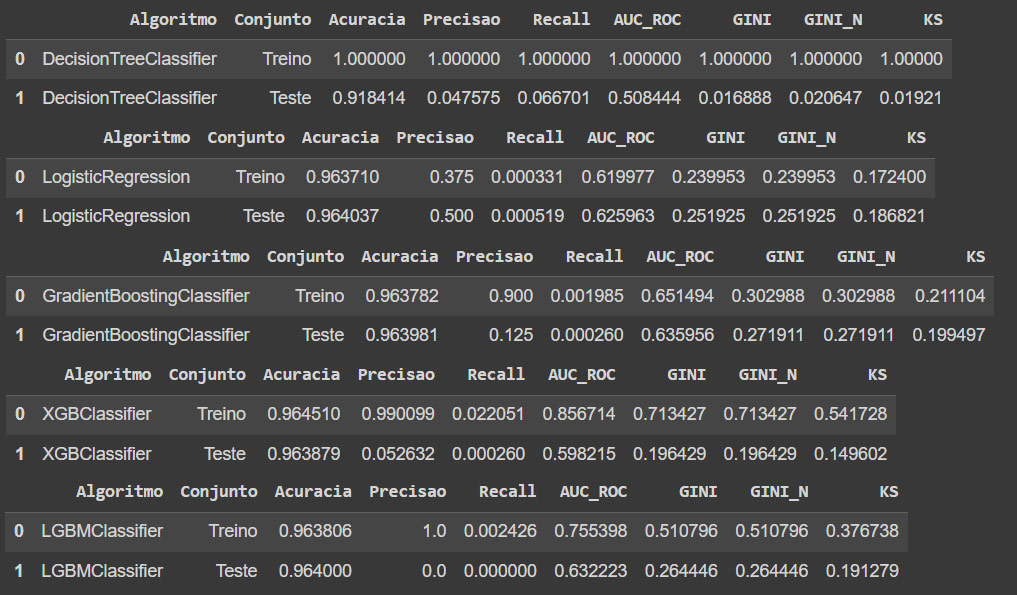
Alguns pontos importantes ao analisar os dados:
- Ficar atento ao overfitting, o modelo pode capturar e decorar, pode ir bem no treino e no teste não tão bem como na imagem acima.
- Após escolha de modelo pode se utilizar alguns recursos para melhorar a performance do modelo.
Escolha do modelo e métricas de referência
Após o treinamento dos modelos foi feito a análise das métricas e escolhido o modelo com base nas informações do case. Atentando sempre para a proximidade dos dados de treino e teste.

E agora é salvo os dados do modelo para implantação.
É muito importante sempre ficar atento ao Split para evitar problemas com os resultados do modelo.
Feature Selection com Feature Importance
O Feature Selection é o processo de seleção de um subconjunto relevante de features (variáveis) a partir de um conjunto maior para que possa ser utilizado pelo modelo.
Para a etapa de Feature Selection que é uma das fases mais importantes, foi feito utilizando duas técnicas diferentes para poder ter um comparativo sobre a diferença das métricas quando feito por técnicas diferentes e aplicadas ao mesmo modelo.
O objetivo aqui é reduzir a dimensionalidade dos dados, mantendo apenas as mais importantes para ser utilizadas pelo modelo.
Onde inicialmente tinha-se 61 variáveis, após a seleção ficou com apenas 14.
Para essa primeira seleção foi feita utilizando o RandomForestClassifier com Feature Importance (poderia ser qualquer outro modelo ou técnica).
O que é Feature Importance
Feature importance é um conceito utilizado em aprendizado de máquina para entender quais características ou variáveis têm maior impacto na previsão de um modelo.
Em essência, o cálculo da importância das variáveis ajuda a identificar quais atributos contribuem mais para a capacidade de um modelo de fazer previsões precisas.
Com isso existem várias técnicas para calcular a importância das variáveis, e a escolha da técnica pode depender do algoritmo de aprendizado utilizado. Veja alguns métodos comuns incluem:
1. Importância baseada em árvores
2. Coeficientes de modelo linear
3. Permutação de variáveis
4. Entre outras
Entender a importância das variáveis pode ser útil para vários propósitos, como:
- Identificar variáveis importantes para a compreensão do problema
- Reduzir a dimensionalidade, focando nas variáveis mais importantes
- Melhorar a interpretabilidade do modelo, explicando como as previsões são feitas
- Realizar engenharia de variáveis, desenvolvendo novas características com base na importância das características existentes.
Detalhes sobre a construção do processo de Feature Selection
Como já citado para essa primeira seleção foi utilizado o RandomForestClassifier com Feature Importance (poderia ser qualquer outro modelo ou técnica). Para mais detalhes do código, acesse o link abaixo.
Código Fonte:
Nessa etapa foi configurado o ambiente e importado todas as bibliotecas úteis para realização da seleção de variáveis.
Foi feito o carregamento dos dados de treino para o processo de Feature Selection e feito uma visualização da estrutura em que se encontrava.
Sem seguida foi removido as colunas desnecessárias nesse momento como ‘Unnamed: 0’, ‘id’. Depois disso uma nova checagem antes de iniciar.
Para iniciar o Feature Selection com o modelo escolhido, primeiro foi separado o target do restante das colunas.
Em seguida instanciado o modelo RandomForestClassifier e realizado o treinamento do modelo com os dados.
Agora foi trabalho a parte de importância das variáveis, onde usando o modelo treinado, é chamado o feature_importances_ que retorna a importância relativa de cada variável no processo de treinamento do modelo.
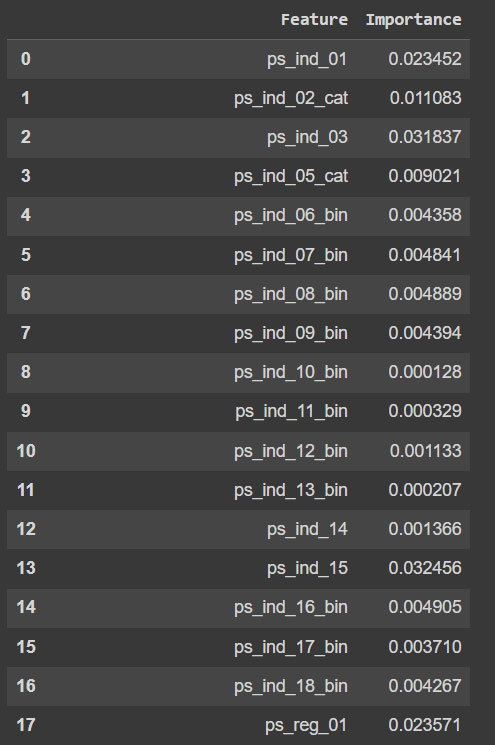
Com isso ele mostra quão significativo para o modelo fazer previsões foi cada variável, isso ajuda na seleção das melhores.
Feito a listagem das variáveis e suas importâncias, é listado e estabelecido um limite de corte para aplicar a seleção.
A seleção será feita pelas variáveis acima do corte.
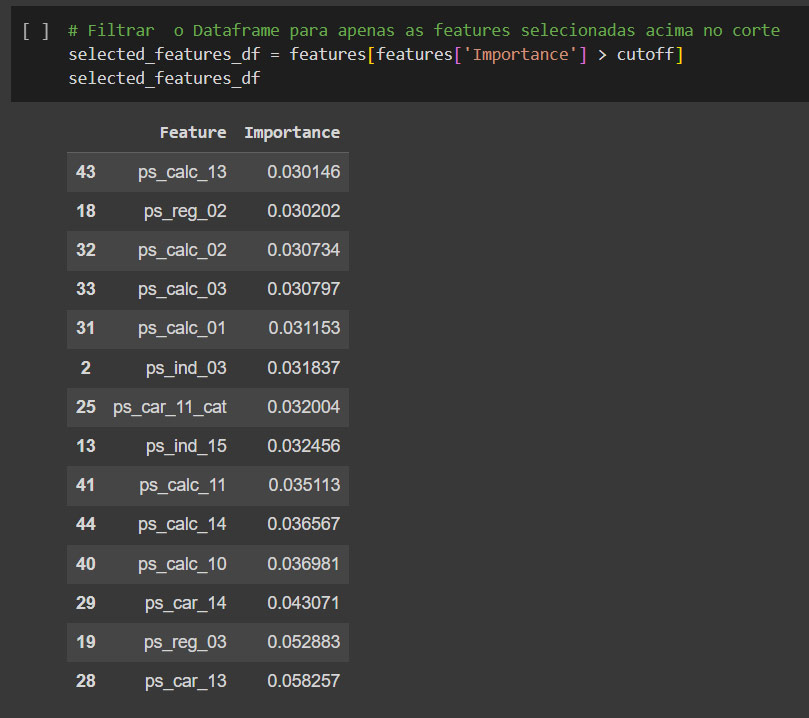
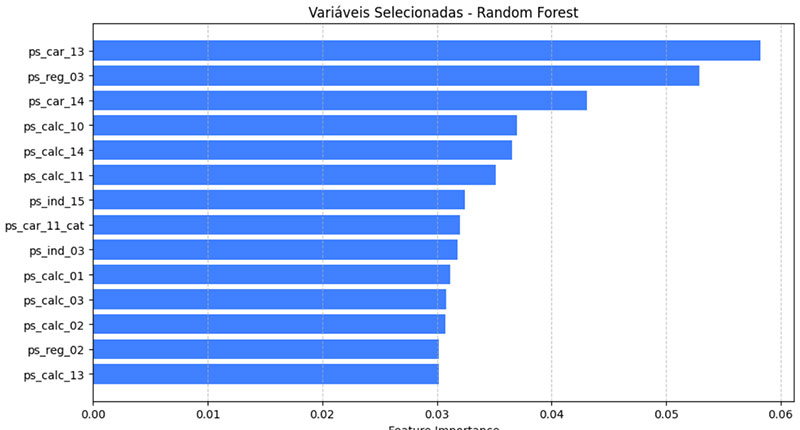
Feito a seleção de variáveis. É criada e salva a lista de variáveis para ser implantado usando arquivo pkl.
Em seguida é carregado a lista de variáveis selecionadas e adicionado nela o target.
Onde será criado um novo dataframe somente com as variáveis ainda utilizando a base de treino.
Em seguida é carregado também a base de teste para que possa ser aplicado a mesma estrutura de variáveis.
E ao final temos nossa ABT para treinamento dos modelos de Treino e Teste para ser utilizado.
Agora vamos para a próxima técnica de Feature Selection.
Feature Selection com RFE (Recursive Feature Elimination)
Para essa feature selection utilizei uma técnica diferente para poder gerar um comparativo e ver a influência da seleção de variáveis no modelo.
O método escolhido aqui é o RFE e o modelo foi a Regressão Logística para selecionar, onde será aplicado na base de treino e teste e gerado uma nova ABT, onde teremos duas ABTs para testar os modelos.
O que é RFE (Recursive Feature Elimination)
RFE, ou Recursive Feature Elimination, é uma técnica de seleção de variáveis utilizada em aprendizado de máquina para escolher automaticamente as variáveis mais importantes de um conjunto de dados.
Ela funciona de forma iterativa, começando com todas as variáveis e eliminando recursivamente as menos importantes com base em algum critério (geralmente a importância das variáveis).
No RFE, o modelo é treinado com todas as variáveis e as menos importantes são removidas sucessivamente até atingir o número desejado ou até que o desempenho pare de melhorar.
Isso reduz a complexidade dos dados, destacando as variáveis mais relevantes, resultando em modelos mais simples e interpretações mais claras.
Detalhes sobre a construção do processo de Feature Selection
Veja a seleção de variáveis com RFE e regressão logística. Caso deseje pode ir direto para o código abaixo ou ver o detalhamento do que foi feito.
Código Fonte: https://github.com/lacostamkt/pcd_porto_seguro_safe_driver_prediction/blob/main/04_porto_seguro_feature_selection-rfe.ipynb
Como em todo projeto, foi feita a configuração inicial e importação das bibliotecas úteis que serão utilizadas.
Inicialmente seria feito RFE com Cross-Validation, mas devido a lentidão do ambiente ficará para uma próxima atualização, ficando apenas o RFE por enquanto.
Agora é feito o carregamento dos dados de treino para iniciar o Feature Selection e uma visualização da estrutura dos dados.
Assim como no anterior é removido as colunas desnecessárias ‘Unnamed: 0’, ‘id’.
Depois é separado as colunas do target, mantendo ele isolado para treinar o modelo.
É instanciado o modelo LogisticRegression do sklearn. Poderia ser outro modelo se desejar.
Uma vez feito isso é treinado o modelo com os dados.
Agora é aplicado o RFE ao modelo treinado informando a quantidade de variáveis desejada. E o RFE vai treinar diversas o modelo com diferentes subconjuntos e eliminar os menos importantes até que reste apenas o número desejado.
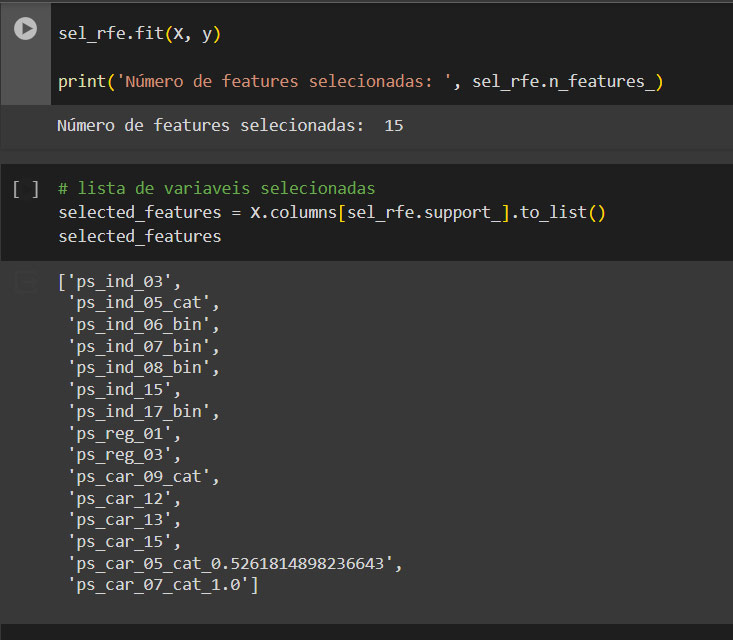
Com os dados do treino é possível ter acesso a algumas informações como o ranking e os coeficientes.
Já com as variáveis prontas é salvar elas em uma lista PKL para implantação.
Feito isso é carregar a lista de variáveis e o target e aplicar a base de treino e teste seguindo a mesma orientação no Feature Selection anterior.
Ao final teremos as ABTs de treino e teste geradas a partir da técnica RFE.
E a partir daqui já podemos partir para o modelo.
Criação dos Modelos
Aqui é a etapa de treinamento do modelo, só que possuímos mais de uma ABT para treinamento do modelo tanto a feita pelo Feature Importance quanto pelo RFE para comparação, os modelos utilizados para treinarem é o mesmo para ambas, onde o que mudará será apenas a fonte dos dados.
Os modelos escolhidos foram os seguintes:
- DecisionTreeClassifier
- LogisticRegression
- RandomForestClassifier
- LightGBM
Onde o maior objetivo aqui é analisarmos os resultados quando utilizados métodos de seleção de variáveis diferentes.
Não trarei todos os comparativos, mas podem ser vistos no arquivo fonte.
Detalhes sobre a construção
Esse é apenas um descritivo rápido do que foi feito na construção dos modelos. Podendo ver todo o código no arquivo abaixo.
Código fonte:
Para construção dos modelos foi feita a importação das bibliotecas que seriam utilizadas, e também da biblioteca PodAcademy que possui funções úteis para agilizar o trabalho.
Preparado o ambiente é feita a leitura dos dados da ABT de treino, e checado para ver como está a estrutura dos dados e também um describe para ver as estatísticas descritivas da base.
Devido ao tamanho da base e para ganho de performance na execução foi feito a seleção de uma amostra aleatória.
A partir dela foi gerada uma nova amostra balanceada baseado no target para que o dataframe contenha a mesma quantidade de eventos e não eventos.
Feito isso temos um novo dataframe mais balanceado em relação aos eventos (sinistros em nossa base é um evento raro).
Depois disso antes de começar a trabalhar os dados foram embaralhados.
Para essa etapa está sendo utilizado a base ABT RFE.
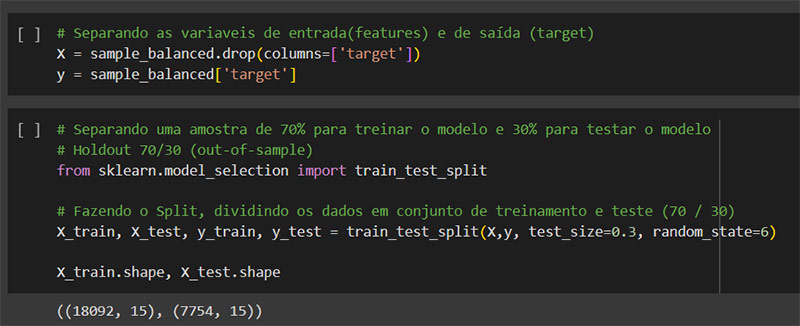
Nessa etapa agora foi separado o target das demais colunas.
Em seguida realizado o SPLIT (70/30) antes de qualquer outra ação para evitar problemas futuros. A parte de test foi reservada para uso no final.
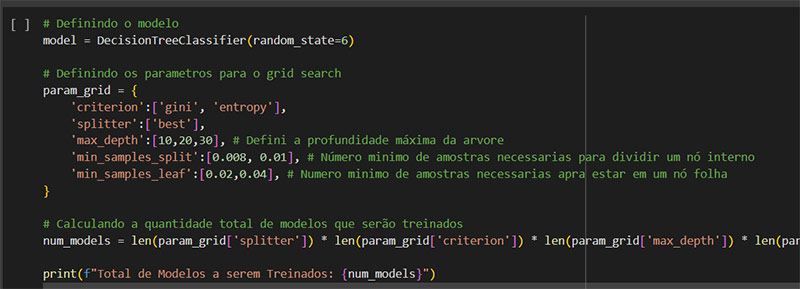
Agora é escolhido o modelo e definido nossa lista de parâmetros para o GridSearch.
Em média cada modelo terá 120 ou mais modelos treinados baseados nos parâmetros, onde cada um deles tem suas características.
O GridSearch é uma técnica usada em aprendizado de máquina para encontrar os melhores hiperparâmetros para um determinado modelo.
Hiperparâmetros são configurações que não são aprendidas pelo modelo durante o treinamento, como a profundidade máxima de uma árvore de decisão ou a taxa de aprendizado de um algoritmo de otimização.
O GridSearch treina e avalia o modelo para cada combinação de hiperparâmetros usando validação cruzada (cross-validation).
Após testar todas as combinações, o GridSearch retorna a combinação de hiperparâmetros que produz o melhor desempenho de acordo com uma métrica especificada, como precisão, acurácia, etc.
Uma vez executado e treinado os modelos, teremos os melhores parâmetros e a melhor pontuação com base na métrica escolhida.
Todos os próximos modelos seguem a mesma estrutura de construção tendo em particular apenas os parâmetros que são característicos de cada modelo.
Para visualizar os dados e avaliar o modelo existe uma função que facilita isso, permitindo ver graficamente os resultados.
Os parâmetros de cada modelo podem ser treinados e otimizados conforme desejar, inicialmente foi dado a lista, mas pode modificar e ver o que altera nos resultados.
Ao final dos modelos treinados foi gerado os artefatos para implantação e salvos em PKL para ser utilizado na escoragem da base de teste.
Comparando as Métricas de RFE e Feature Importance
Como são vários modelos, fiz a comparação apenas do modelo que apresentou melhores métricas segundo o case do projeto, no caso escolhi o LightGBM.
O RFE (Recursive Feature Elimination) e Feature Importance são duas abordagens diferentes para seleção de características em modelos de aprendizado de máquina.
Parte desse projeto teve como objetivo comparar os métodos de seleção de variáveis e os resultados gerados por eles quando aplicados ao mesmo modelo.
Entendendo um pouco de cada um deles:
O RFE é um método que trabalha iterativamente removendo variáveis menos importantes de um conjunto inicial de variáveis.
Ele treina o modelo com todas as variáveis e, em seguida, remove aquela que tem o menor impacto no desempenho do modelo. Esse processo é repetido até que o número desejado de variáveis seja alcançado.
Já o Feature Importance é uma técnica que avalia a importância relativa de cada variável no desempenho do modelo.
A principal diferença entre os dois é que o RFE é um método de seleção de variáveis que remove variáveis menos importantes, enquanto a Feature Importance calcula a importância de cada variável individualmente sem remover nenhuma delas do conjunto de dados.
Comparação de Resultados
Gráfico de Seleção de Variáveis – RFE
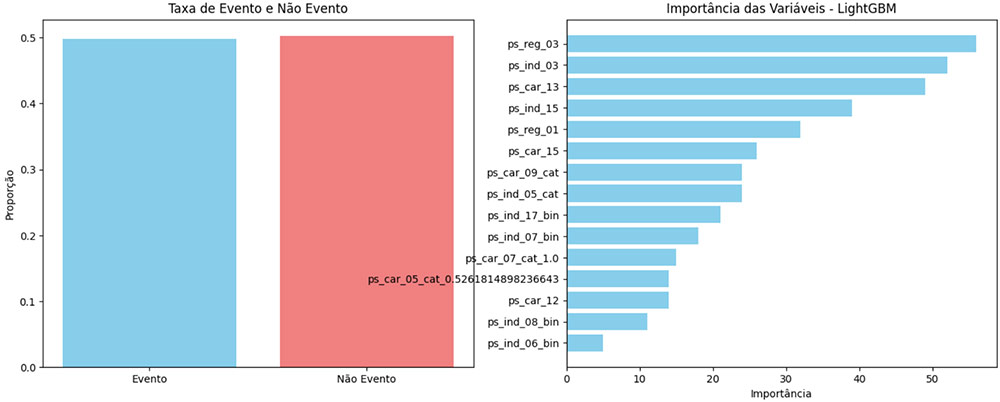
Gráfico de Seleção de Variáveis – Feature Importance
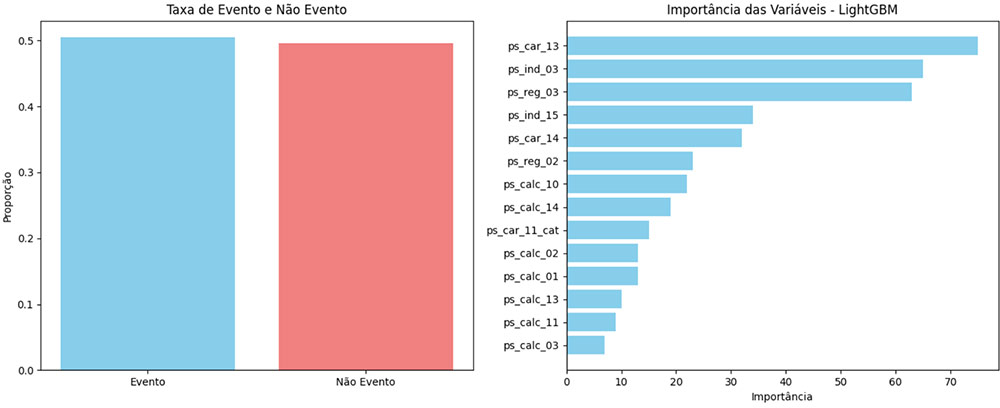
Ambos os gráficos acima apresentam a utilização da ABT tanto de RFE quanto Feature Importance treinados pelo modelo LightGBM, porém notamos algumas diferenças importantes entre eles:
As variáveis mais importantes para o RFE: ps_reg_03, ps_ind_03, ps_car_13 e ps_ind_15.
As variáveis menos importantes para RFE são: ps_car_12, ps_ind_08_bin e ps_ind_06_bin.
As variáveis mais importantes para o Feature Importance: ps_car_13, ps_ind_03, ps_reg_03 e ps_ind_15.
As variáveis menos importantes para RFE são: ps_calc_13, ps_calc_11 e ps_calc_03.
Observações:
Note que ambas as variáveis mais importantes dos modelos estão na seleção dos dois métodos. E ambas foram consideradas extremamente importantes para o treinamento.
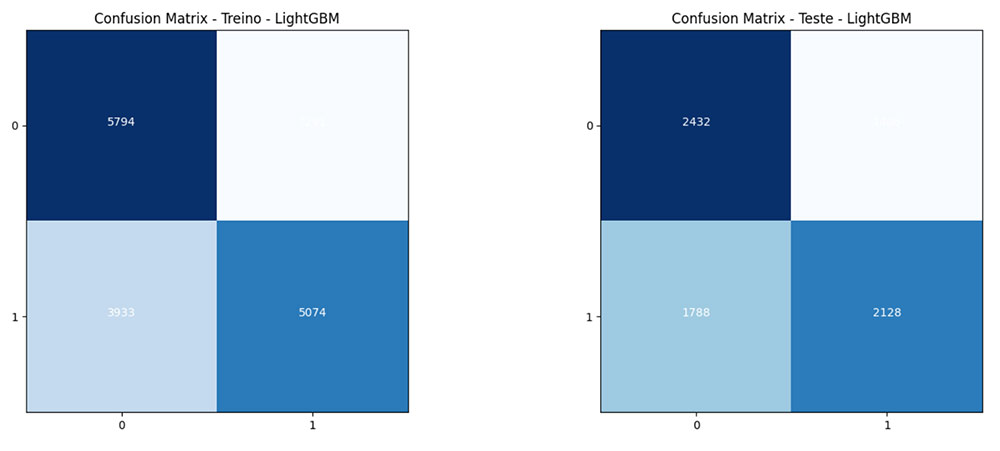
Matrix de Confusão – RFE
Matrix de Confusão – Feature Importance
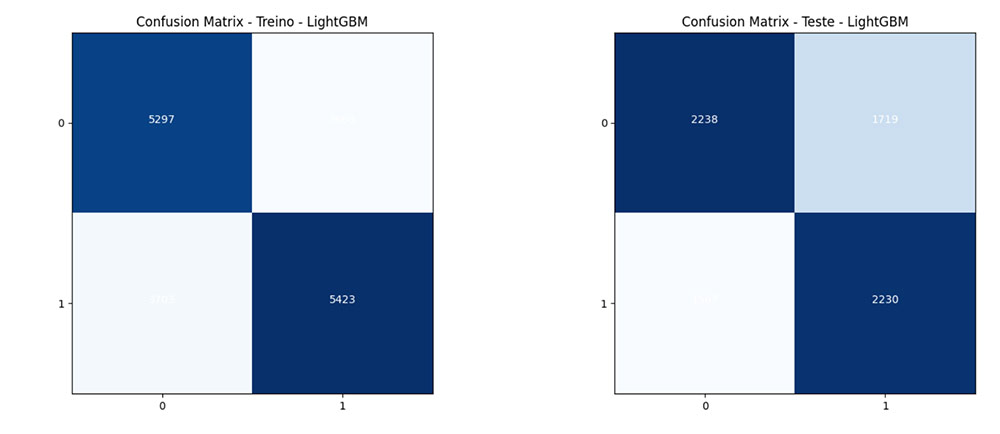
Observações:
Com base na análise dos gráficos de confusão, podemos concluir que o modelo LightGBM demonstra um desempenho satisfatório na classificação das instâncias do conjunto de dados em questão para ambas técnicas.
ROC Curve – RFE
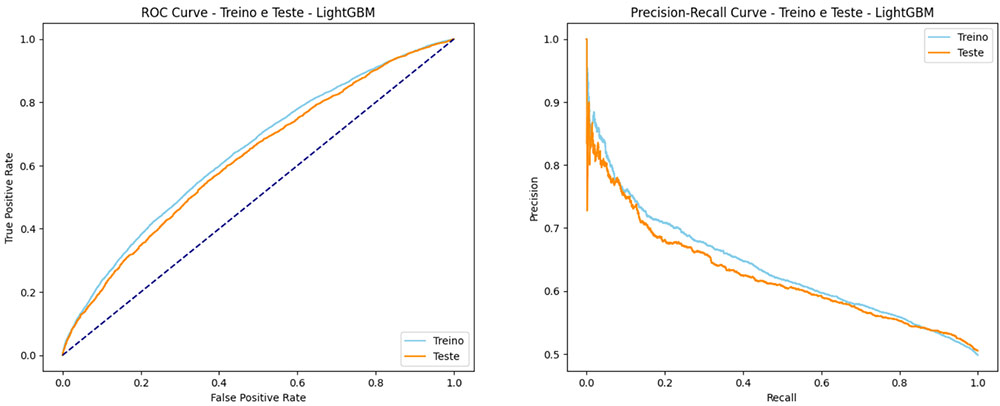
ROC Curve – Feature Importance
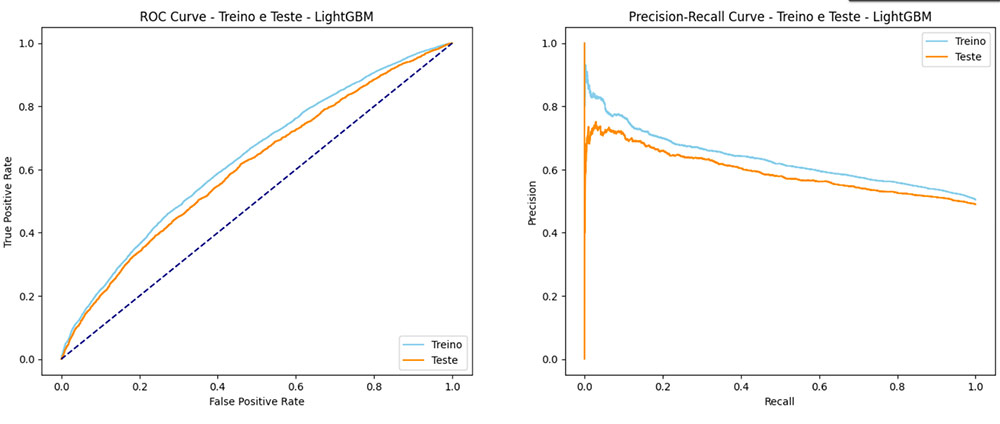
Observações:
Gini – RFE
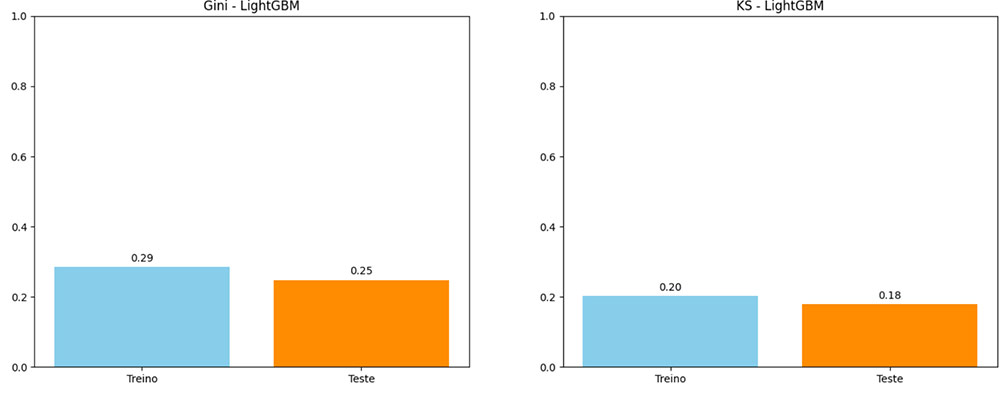
Gini – Feature Importance
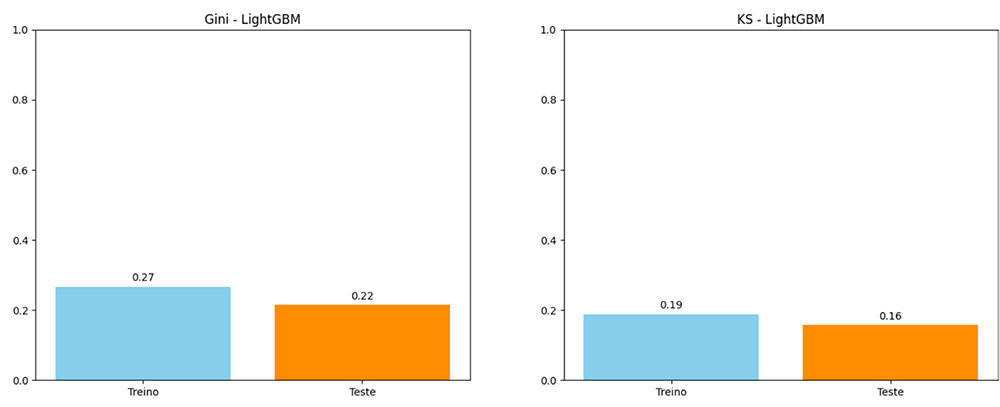
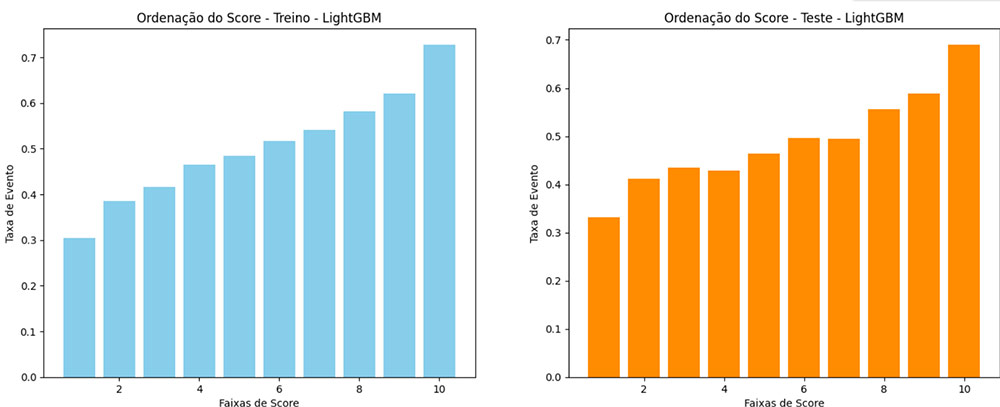
Ordenação de Score – RFE
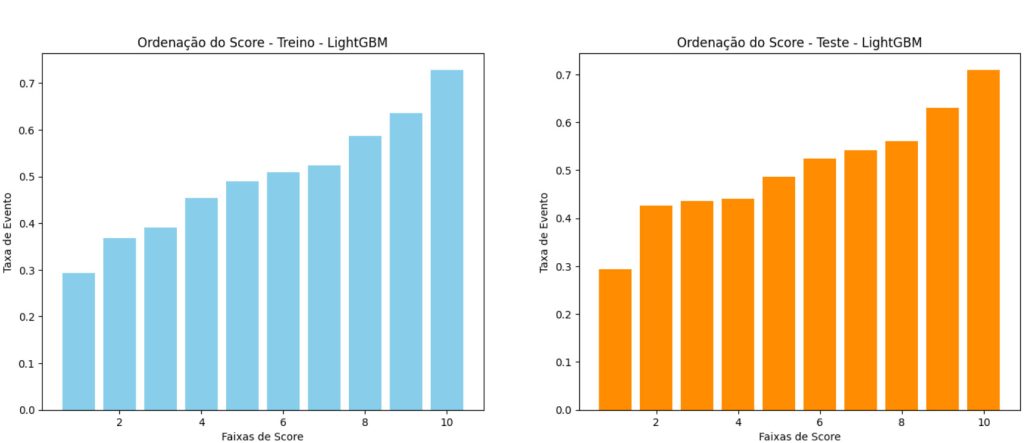
Ordenação de Score – Feature Importance