Como proposta de estudo e melhoria das habilidades como Cientista de Dados foi proposto um desafio na área de concessão de crédito e para isso foi realizado o desenvolvimento do projeto de análise de crédito, onde foi feito o Modelo de Application.
Nesse projeto foram utilizados recursos como:
- CRISP-DM
- PySpark
- Python
- Feature Engineer
- Feature Selection
- Machine Learning
- Hiperparâmetros
- Modelo de Baseline
- Regressão Logística e LightGBM
Índice
- Código do projeto de Análise de Crédito – Modelo Application
- Nasce uma Necessidade: Apresentação do Case
- A solução para o Negócio
- O que é a Concessão de Crédito (Application Scoring)
- Entendendo o Framework CRISP-DM
- Desenvolvimento do Projeto usando o CRISP-DM
- Entendimento do Negócio
- Entendimento dos Dados
- Preparação dos Dados
- Modelagem
- Avaliação
- Implantação
- Dificuldades durante o projeto e Insights
Código do projeto de Análise de Crédito – Modelo Application
Acesso ao código completo do projeto, para facilitar o entendimento do código que está comentado com as devidas informações e orientações necessárias. É recomendado ler todo o conteúdo para ver a associação ao CRISP-DM e entender as soluções abordadas.
Os arquivos estão numerados e representam a ordem que foram executados apenas para ilustrar o processo.
Link para Projeto no GitHub: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application
Etapas:
- Feature Engineer
- Modelo Baseline
- Feature Selection
- Modelo de Regressão Logística / LightGBM
Nasce uma Necessidade: Apresentação do Case
Aqui apresento o case do projeto, com a evolução do mercado e a necessidade de se manter competitivo nasce uma necessidade relacionada a concessão de crédito para tornar o trabalho mais eficiente e gerar melhores resultados.
A PoD Bank, uma startup do segmento financeiro que concede crédito para população com pouca informação de crédito, ganhou mercado e maturidade.
Com isso, começou a sentir necessidade de um modelo de crédito para amparar suas decisões e deixar de depender apenas do BI (Business Intelligence).
Decidiu, então, montar uma área de Planejamento e Modelagem de Crédito focada em modelos estatísticos.
No entanto, a Head de Crédito está começando a ficar preocupada pois, embora o crescimento da carteira de clientes PoD Bank seja expressivo, ela está vendo a inadimplência do mercado subir.
Por isso, quer solicitar à área de Planejamento e Modelagem da PoD Bank um modelo de crédito que tenha capacidade de gerar um score de risco para contratação de produtos de crédito.
Fonte:
https://www.kaggle.com/competitions/pod-academy-analise-de-credito-para-fintech
A solução para o Negócio
Para resolver o problema foi feita a criação de um modelo estatístico que impacte no faturamento da empresa gerando mais eficiência em relação apenas a utilização do BI.
Além de auxiliar na criação das políticas de crédito e permite um melhor planejamento com base nas métricas geradas pelo modelo.
Com a geração do modelo e do Score será possível entender melhor o público e tomar ações mais estratégias reduzindo a taxa de inadimplência para minimizar os riscos e aumentar o faturamento.
E para auxiliar no planejamento e solução desse problema é utilizado diversos recursos entre eles o framework CRISP-DM para o melhor andamento do projeto.
A seguir veja o que é concessão de crédito e um pouco mais sobre modelo Application, e também as etapas do projeto seguindo o CRISP-DM.
O que é a Concessão de Crédito (Application Scoring)
O modelo de Application é utilizado principalmente na solicitação de crédito, onde é utilizado para avaliação da probabilidade do solicitante cumprir suas obrigações de pagamento.
O modelo de Application analisa os dados do solicitante disponíveis como histórico de crédito, renda, empresa, operações financeiras e outras informações para prever o risco de inadimplência.
A obtenção desses dados podem ser feitas através de bureau de dados (alguns mais conhecidos como Boa Vista SPPC, Serara Experian, B3, Portal da Transparência, Banco Central do Brasil, quod entre outros).
Para acesso aos dados é recomendado serem feitos via API para sempre ter dados mais atualizados e em tempo real para consulta. Essas informações ajudarão no modelo e na tomada de decisão.
O objetivo do modelo é auxiliar na tomada de decisão sobre a concessão de crédito solicitada, e assim minimizar o risco de perdas pela organização financeira.
Entendendo o Framework CRISP-DM
O CRISP-DM é um framework/modelo utilizado para orientar projetos de análise e ciência de dados.
Através de um conjunto de boas práticas ele ajuda a fornecer organização e clareza no desenvolvimento de projetos da área de dados, facilitando durante o decorrer do trabalho.
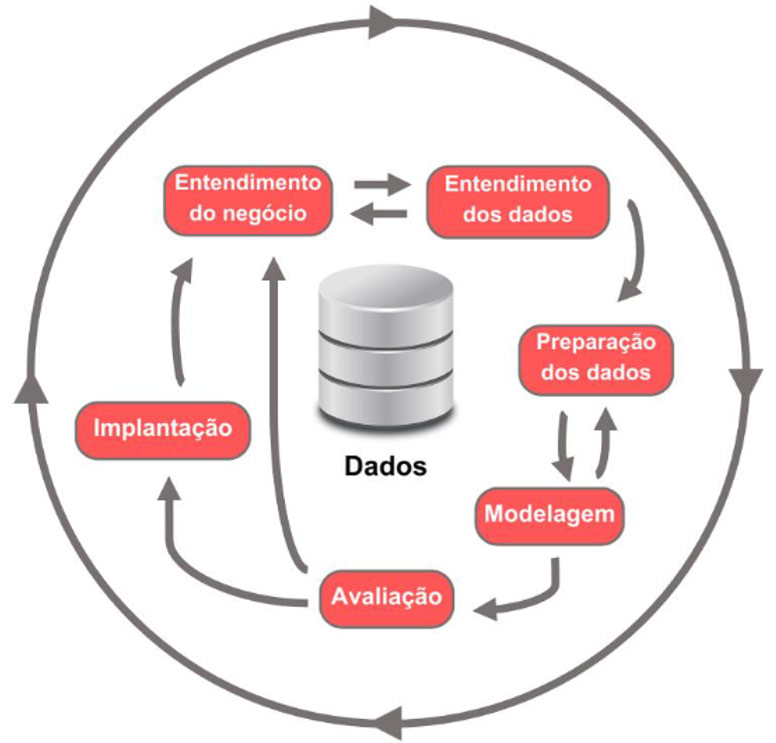
Etapas do CRISP-DM:
– Entendimento do Negócio: Etapa para compreender o foco e os objetivos do projeto, necessidades do cliente e o contexto do problema a ser solucionado. Basicamente é entender qual problema de negócio precisa ser resolvido.
– Entendimento dos Dados: Entender todo o processo envolvido na coleta, exploração e mineração dos dados disponíveis para solucionar o problema. Aqui procura-se entender sobre as variáveis, bem como realização de “testes de sanidade”
– Preparação dos Dados: Etapa onde é realizado todo o tratamento dos dados (ajuste em tipos de variáveis, agrupamento de bases, padronização, normalização, ajustes, etc.) para deixar a base pronta para fase de modelagem.
– Modelagem: Treinamento do modelo e otimização de hiperparâmetros se necessário, nessa etapa são realizadas seleção de variáveis, treino de modelos desafiantes e otimizações.
– Avaliação: Verifica se a solução desenvolvida resolve o problema de negócio identificado no início do projeto. Podem ser utilizados indicadores como acurácia, precisão e recall para avaliar a qualidade do modelo. Nessa etapa é comparado os resultados, verifica se as expectativas e critérios de sucesso definidos.
– Implantação: Etapa para implantar a solução desenvolvida de maneira que possa começar a gerar resultados para o cliente. A partir daqui é implantar e monitorar o modelo desenvolvido através dos critérios definidos.
Desenvolvimento do Projeto usando o CRISP-DM
Entenda o que foi feito em cada etapa do desenvolvimento do projeto de Modelo Application para Concessão de crédito.
Entendimento do Negócio
A PoD Bank é uma startup do segmento financeiro que trabalha com a concessão de crédito e hoje possui poucas informações sobre os solicitantes, porém vem ganhando mercado.
Com o crescimento vem também a necessidade de melhorar os processos internos entre eles o de concessão de crédito, o objetivo hoje é melhorar a tomada de decisões e escalar o negócio que hoje é feito apenas através de BI.
Para isso ela deseja criar uma área de planejamento e modelagem de crédito focado na utilização de modelos estatísticos para uma melhor performance e escalonamento do negócio com decisões mais assertivas.
Contudo existe uma preocupação em evidência e de grande importância para ser solucionada, mesmo com o crescimento da carteira de crédito a inadimplência do mercado vem subindo.
E com isso surge a necessidade da área de planejamento e modelagem criar um modelo de crédito capaz de gerar um score de risco (Scorecard) para a contratação de produtos de crédito. Esse recurso irá auxiliar na tomada de decisão tornando mais preciso o processo de aprovação.
E para ajudar no desenvolvimento e resolução desse projeto foi utilizado o CRISP-DM para organização, planejamento e execução das etapas.
Objetivos:
- Melhorar a concessão de crédito sem depender de BI
- Criação de modelo de crédito para auxiliar nas domadas de decisões
- Criação de modelo capaz de gerar score de risco (Scorecard) para contratação de produtos
- Melhorar a capacidade de identificação
Critérios de avaliação para sucesso do projeto:
- Métricas: KS, Gini, ROC-AUC
- Ordenação do score em 10 faixas
Entendimento dos Dados
Uma das etapas mais importantes do processo de construção do modelo, já que são os dados que ajudarão a definir o resultado final.
Nessa etapa é fundamental compreender todo o processo que vai desde a coleta dos dados, exploração e mineração dos dados disponíveis para serem utilizados e desenvolver a solução do problema.
Nessa etapa verifiquei que dados teremos disponíveis para serem utilizados pelo modelo que será desenvolvido.
Entre eles podem ser:
- Base de público
- Books de variáveis
- Variáveis de Bureau
Os dados a serem utilizados se encontram disponibilizado em formato CSV dividido em arquivos que precisaram ser tratados para ser utilizado no projeto.
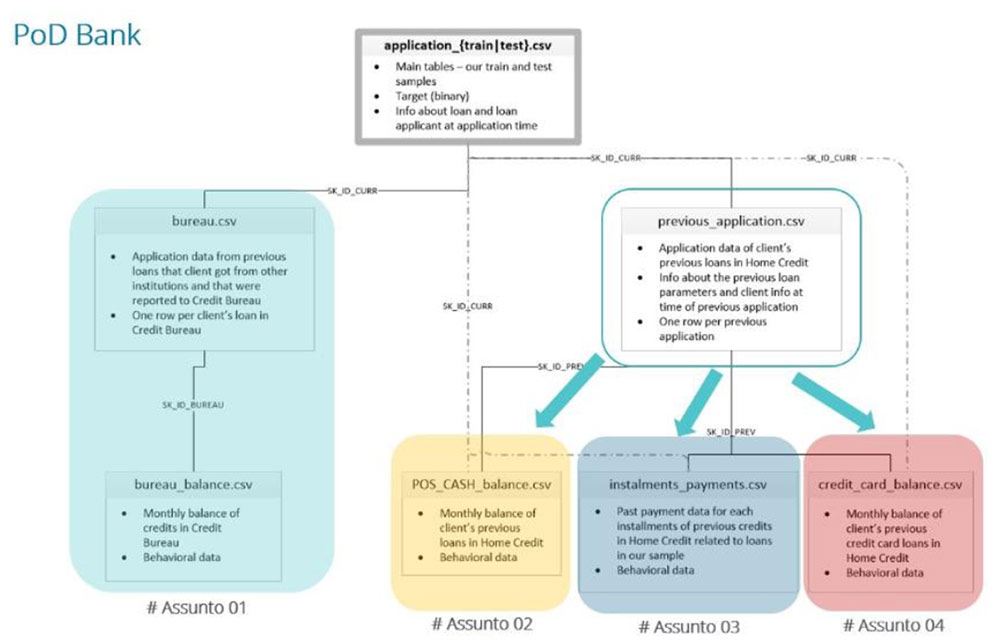
Bases disponíveis e seus respectivos conceitos:
- Application Train – Base de público para treino do modelo;
- Previous Application – Aplicações de empréstimos anteriores de clientes na PoD Bank;
- Installments Payments – Histórico de pagamentos de empréstimos anteriores na PoD Bank;
- POS Cash Balance – Balanço mensal de empréstimos anteriores em dinheiro na PoD Bank;
- Credit Card Balance – Saldos mensais de cartões de crédito do cliente na PoD Bank;
- Bureau – Dados de outras instituições financeiras;
- Bureau Balance – Informações mensais sobre créditos anteriores do cliente em outras instituições financeiras;
- Application Test – Base de público para escoragem.
- Também foram disponibilizados os metadados para melhor entendimento dos dados.
Utilizar o CRISP-DM é essencial para o projeto, pois se torna um facilitar já que procura-se entender os dados disponíveis e as variáveis que serão utilizadas.
Conhecendo seu público
E etapa de entendimento dos dados é uma também o momento de conhecer seu público e os possíveis cenários que os dados trazem.
Podendo ser feito o estudo do público, e como eles já se comportam com os produtos os produtos atuais.


Preparação dos Dados
Etapa onde foi realizado todo o processo de tratamento de dados nas tabelas para deixar a base pronta para ser utilizada na modelagem.
Nessa etapa foram aplicadas diversas técnicas para poder adequar os dados para uso:
- Utilização de dados de Bureau
- Aplicação de agregação para geração de novas variáveis;
- Joins entre bases;
- Padronização dos dados;
- Aplicação de filtros sempre que necessários;
- Ajuste nos tipos de variáveis.
Na preparação dos dados foi aplicado o Feature Engineering nas bases, onde foi criado variáveis preditivas a partir dos dados disponíveis. Aqui foi feito o Feature Store ou Book de Variáveis.
Através das agregações dos dados foram gerados mais variáveis para utilização do processo de Feature Selection e pelo modelo.
Após efetuar as agregações nos Dataframes para geração das variáveis foi realizado o merge (Join) para concatenar todos os dados obtidos em um único Dataframe sempre respeitando a granularidade do indivíduo para ser utilizado na modelagem.
Feature Store ou Book de Variáveis
Esse recurso muito importante que é Feature Store, que é sumarizar as informações importantes do solicitante contido nas bases gerando assim mais variáveis para facilitar o uso tanto na análise de dados como na utilização pelo modelo a ser construído.
Aqui são construídas variáveis explicativas utilizando por exemplo valores máximo e mínimo, total e média para explicar o comportamento.
É fundamental ficar atento a granularidade dos dados para poder ter dados de mais qualidade para utilização.
Detalhes sobre o processo de preparação dos dados:
Essa etapa consiste em trabalhar os dados para serem utilizados, devido ao grande volume de dados tanto interno como externos(Bureau) o processo foi dividido em etapas para que pudesse ser realizado.
– Credit Card Balance
A primeira etapa foi nos dados do Credit Card Balance que consistia em ler os dados (para isso foi utilizar o Spark) e ver como estavam.
Após início foi feita a criação das flags para auxílio na visão temporal dos dados.
Em seguida foi sumarizar na visão do cliente onde foi criado as principais agregações:
- Máximo
- Mínimo
- Total
- Média
Esse processo foi criado para várias variáveis conforme a necessidade e o tipo de informação.
Uma vez realizado o processo os dados foram salvos.
– Installments
O mesmo processo foi realizado com esses dados seguindo as mesmas etapas pela similaridade de variáveis não foi necessário nenhuma ação diferente.
– Bureau Balance
Esses dados eram mais simples e com menos variáveis/colunas para serem preparados, além da visão temporal também foram criadas flags com base no STATUS para gerar mais informações para agregação.
– Bureau
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/4_bureau_feature_engineering.ipynb
Os dados foram preparados da mesma maneira seguindo a visão temporal e também as flags para categoria CREDIT_ACTIVE.
Ao final do processo a base Bureau que era a que possuia o ID de identificação do cliente e da operação foi feito o JOIN com a Bureau Balance e salvo para uso.
– Pos Cash Balance
Esses dados são internos e foram preparados e tratados seguindo o mesmo processo dos anteriores criando a visão temporal.
– Previous Application
Essa base era a mais difícil devido a quantidade informações o que deixou o processo muito lento, seguindo o mesmo padrão de visão temporal das anteriores.
Para solucionar o problema foi necessário dividir em etapas e também foi gerado no formato .parquet que apresentou uma performance melhor naquele momento.
– Application Train (base do público)
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/7_application_train_bureau_agg.ipynb
Nessa etapa foi feito o JOIN com as bases geradas anteriormente, mais uma vez devido ao volume de dados foi necessário dividir em etapas para facilitar o processamento.
Também utilizando o Spark e formato de arquivo .parquet.
Ao final tinha a base application Train com o total de 7852 variáveis.
– Application Test
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/8_application_test_bureau_agg.ipynb
O mesmo processo anterior foi aplicado nessa base. Com exceção de não ter a variável TARGET por ser a base de teste que será utilizada futuramente para escoragem do modelo.
O maior desafio nessa etapa foi o baixo poder de processamento (utilização de ambiente local ou Colab) o que fez com que fosse necessário reduzir a visão temporal de 36 ou 24 meses para 12 meses.
Mas nos arquivos foi mantido uma variável que facilmente pode ser ajustada para o período desejado e o código pode ser executado para gerar os arquivos na visão temporal desejada sem maiores complicações, nesse caso é necessário ajustar e executar todos os arquivos para gerar novos dados e analisar utilizando esses novos dados.
Modelagem
Nessa etapa foi dado início do treinamento do modelo assim como uma eventual otimização de hiperparâmetros.
- Criação de Modelo Baseline
- Seleção de Variáveis
- Treino de modelos – Baseline, Modelo Principal e Desafiante (LightBGM)
- Otimização de hiperparâmetros.
Principais métricas para avaliação definidas no entendimento do negócio
- Acurácia
- Precisão
- Recall
- ROC-AUC
- Gini
- KS
Criação do Modelo Baseline
Para ajudar no desenvolvimento do modelo principal foi criado o Modelo Baseline (o mais simples possível) que serve de referência para o que estamos fazendo, para podermos ajustar a performance do modelo.
No final o modelo principal deverá ter uma performance melhor que o modelo Baseline caso contrário pode ter algo errado e será necessário uma revisão.
Detalhes sobre a construção do Modelo Baseline
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/9_modelo_baseline.ipynb
O modelo baseline possui os importes das principais bibliotecas utilizadas para construção do modelo (Numpy, Pandas, Seaborn, Matplotlib, Sklearn, XGBoost e LightGBM).
Foram criadas funções de métricas do modelo para facilitar a apresentação e visualização das métricas, e assim auxiliar na escolha do modelo e suas métricas como referência.
Foi executada a etapa de importe dos dados de treino e teste. Em seguida feito o Split dos Dados.
Importante ficar atento que todo o processo de preparação é feito depois do SPLIT para evitar data leakage (vazamento de dados).
Nesse processo de preparação dos dados de treino foi feita a separação das variáveis categóricas e numéricas e o tratamento.
– Variáveis Categóricas:
- Realizado processamento de imputação para valor mais frequente;
- Utilização do Target Encoder (Preenche com a média da incidência da variável).
– Variáveis Numéricas:
- Ajustado para substituir os missing pela mediana;
- Não foi utilizado a média devido aos outliers (tem risco de sensibilidade), mas pode ser feito testes com a média, pode ser situacional, em versões futuras irei trazer a comparação;
- Foi feita a padronização (a aplicação dessa técnica facilita o uso dos dados pelos modelos, existem algoritmos que podem ser mais sensíveis e isso já deixa pronto pra aplicação).
– Criação de Pipeline
Foi utilizado Pipeline para organizar o processo de execução, dessa forma foi possível obter o fluxo de trabalho em etapas. Isso torna a preparação dos dados mais rápida e também facilita a otimização.
Após isso os dados de treino e teste estão prontos para treinar o modelo.
– Treinamento dos Modelos
Nessa etapa do modelo baseline foi feito o treinamento dos modelos escolhidos (DecisionTreeClassifier, LogisticRegression, RandomForestClassifier, GradientBoostingClassifier, XGBClassifier e LightGBM) de forma mais simples, foram usados as bases de teste e treino para obter as métricas.
– Análise de Métricas dos Modelos
- Ficar atento ao overfitting, isso pode acontecer quando o modelo captura e decora, ele pode ir perfeito no treino e não tão bem no teste como pode ver na imagem;
- Existem recursos para reduzir o overfitting:
- Divida seus dados adequadamente (aqui cabe atenção na hora de fazer o Split);
- Aplique técnicas de regularização (experimente diferentes técnicas e escolha a que melhor se adequa ao seu conjunto de dados e modelo);
- Utilize validação cruzada;
- Realize a seleção de recursos;
- Ajuste os hiperparâmetros;
- Aumente a quantidade de dados (mais informações para o modelo, assim ele aprenderá e melhor será sua capacidade de generalização);
- Experimente diferentes modelos;
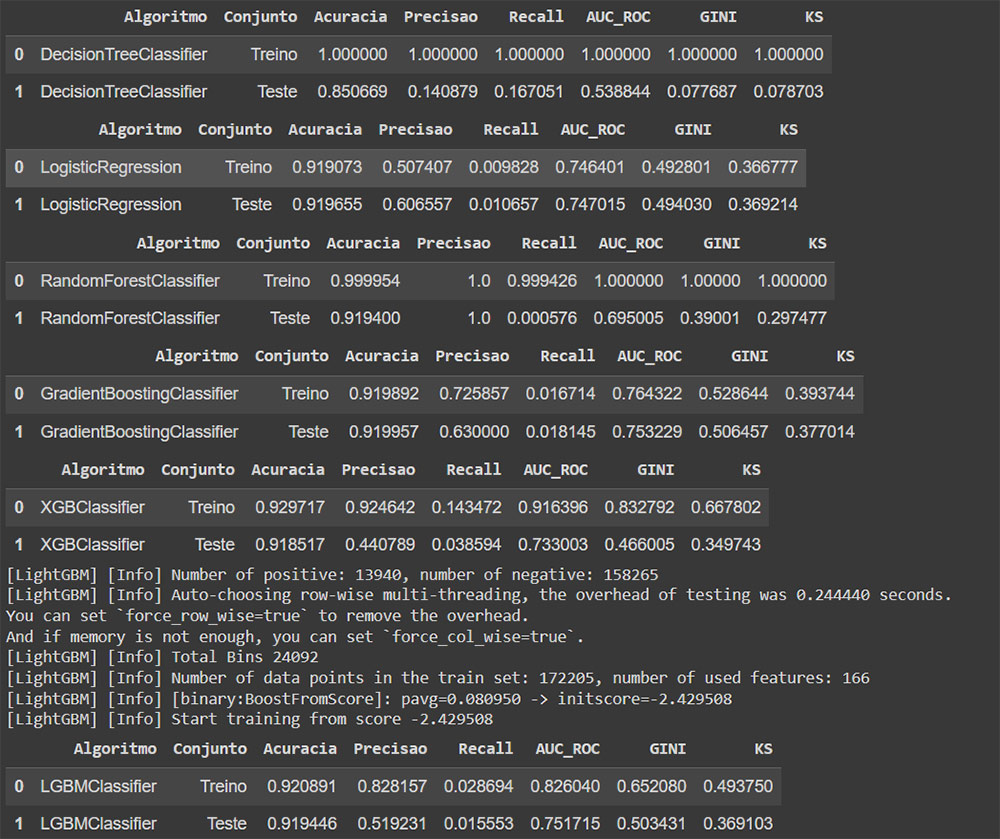
– Escolha do Modelo e Métricas de Referência
Após a análise das métricas foi feita a escolha do modelo. O modelo escolhido foi o LightGBM pela métricas (ROC-AUC, GIni e KS) apresentadas e proximidade entre os dados de Treino e Teste.
Após essa etapas foi gerado o Score para ser analisado e também o arquivo PKL com os dados do modelo escolhido.
Para isso a biblioteca usada foi a pickle, ela ajuda no controle dos objetos que serializou, para utilizar como referência posteriormente.
Sobre o modelo baseline vale ressaltar a importância de dar atenção ao processo de preparação dos dados que deve ser feito depois do SPLIT.
A métrica utilizada foi com base na recomendação do case na fase de entendimento do negócio. E a recomendação de uso foi o ROC-AUC.
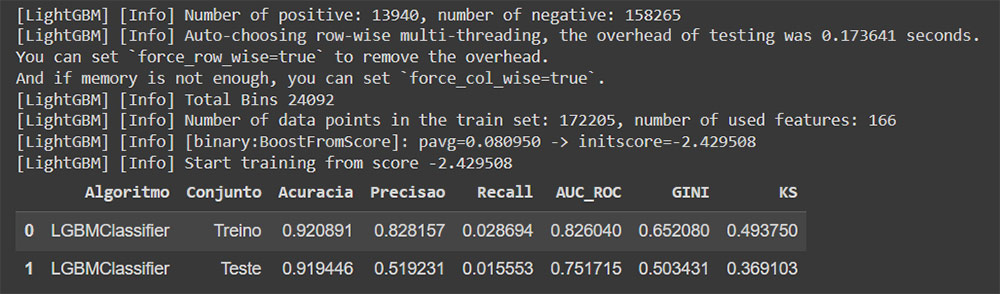
Feature Selection
Agora é a etapa de Feature Selection, uma das mais importantes pois aqui começa a seleção de variáveis para construção do modelo principal e desafiante.
A Feature Selection é o processo de escolher um subconjunto relevante de features a partir de um conjunto maior de variáveis disponíveis.
Nossa base de treino no momento conta exatamente com 7852 colunas (features).
O objetivo dessa etapa é reduzir a dimensionalidade dos dados, mantendo apenas as features mais informativas e importantes para serem utilizadas na criação do modelo e descartar as menos relevantes.
Detalhes sobre a construção do processo de Feature Selection
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/10_feature_selection_base_final.ipynb
Na execução dessa etapa irei basicamente trabalhar na base de treino para selecionar as variáveis mais relevantes para o modelo. E para facilitar esse processo ele pode ser dividido em etapas.
Primeiramente foi feito a importação das bibliotecas que podem ser uteis durante todo o processo e que facilitarão a realização do trabalho.
Então para isso selecionei as mais comuns de uso do dia a dia e também a biblioteca do algoritmo (embora tenha sido utilizado um algoritmo, pode utilizar outros para teste) escolhido para realizar a seleção.
Criação de Funções Auxiliares para Agilizar o Processo
As funções visam dar mais agilidade ao processo, já que essa etapa é comum na criação de modelos, isso pode facilitar muito o dia a dia do Cientista de Dados.
– Função para gerar dataframe com metadados das colunas:
Ele contém nome da variável, tipo, quantidade de nulos, percentual de nulos e cardinalidade. Informações essenciais para tomada de decisão na escolha das variáveis.
Uma forma de facilitar a visualização de como estão as variáveis atualmente e seu preenchimento.
– Função para remoção de features altamente correlacionadas
Essa função é extremamente útil, como inicialmente existe um grande número de variáveis (total de 7852) calcular e verificar a relação entre elas irá facilitar muito.
Aqui você já automatiza o processo e elimina uma grande quantidade de variáveis correlacionadas baseado no limite imposto na função.
Você pode fazer testes aqui para ter uma melhor controle da seleção de features.
É importante passar por essa etapa, pois quando estão muito correlacionadas podem gerar redundância e ter mais de uma variável que explicam a mesma coisa.
Aqui foi utilizado como padrão 0.5, mas pode ser feito testes com outros valores para ver o comportamento das variáveis selecionadas.
– Função de amostragem
O papel dela é simples, gerar uma amostra para construção do modelo, isso é extremamente útil para grande volume de dados. Isso ajuda em casos onde tem limites de processamento.
Aqui a função sample extrai uma amostra aleatória dos dados disponíveis, e para garantir a qualidade da amostra foi definido o random_state=42 que serve para que o código possa ser reproduzido novamente com os mesmos resultados. Caso não utilize irá ter uma amostra diferente todas as vezes.
O número escolhido (42) pode ser qualquer um e serve apenas de referência para execução.
– Função de variância
Calcula e verifica a variância das variáveis.
No conjunto de variáveis que temos ela checa sua variação, se ela não varia acaba que não tem poder preditivo sobre o TARGET tornando ela irrelevante para o modelo.
Você pode também controlar o nível de variância aceitável na função. Sempre cabe testar para chegar a resultados melhores.
– Função Feature Importance
Primeiramente essa função utiliza uma amostra e remove o ID e o TARGET da base para checar a importância das variáveis.
Ela faz todo o tratamento de missing e imputação, inserindo média para as variáveis numéricas, e valores mais frequentes para as categóricas.
Nessa função foi utilizado o Gradient Boosting, porém pode utilizar outros algoritmos e métodos para testar, o impacto desses testes não devem ser tão significativos entre eles.
Além disso foi aplicado o LabelEncoder nas variáveis categóricas.
Mas pode ser utilizado outras técnicas como Target Encoder ou One Hot Encoder, essa etapa embora exista mais de uma opção a variação não acaba sendo grande, porém sempre tem espaço para testes.
– Função var_selection (seleciona as variáveis)
A principal função que irá selecionar e retornas as melhores variáveis segundo os parâmetros que fornecemos.
Ela utiliza as funções anteriores para poder selecionar e tratar os dados aplicando as técnicas para seleção.
Ela sintetiza todo o processo de seleção para facilitar para o cientista de dados, visto que é comum em toda modelagem.
Você define sua base de treino e ela executa uma série de tarefas:
- Ela verifica o preenchimento com percentual definido;
- Gera a amostra;
- Remove todas as variáveis altamente correlacionadas;
- Remove as variáveis constantes;
- Seleciona as variáveis escolhidas e armazena;
- Aplica o algoritmo escolhido para verificar a importância das variáveis e mantém as maiores que zero.
Nessa etapa você pode testar outras técnicas de seleção de variáveis (PCA, RFE, SFS, SBS, etc.).
Bom até aqui falamos das funções que fazem todo o trabalho pesado, então para realizar o processo a partir daqui é simples.
Primeiro é fazer leitura dos dados de treino para utilização pela etapa de Feature Selection. Nesse ponto os dados já foram preparados para utilizarmos técnicas de seleção de variáveis.
Como já dito dentre as técnicas anteriores de preparação dos dados foram criadas várias colunas de agregação para gerar novos dados.
Uma vez lido os dados é utilizar a função vars_selection fornecendo as informações para ela realizar todo o trabalho.
Após a seleção de variáveis é gerada a lista com todas e adicionado novamente o ID e TARGET e salvo a lista da base treino.
O mesmo processo é realizado com a base de teste com exceção do TARGET que é removido. Essa base será utilizado para escoragem posteriormente como Out of Sample. Agora é dar início a criação do modelo principal.
Criação do Modelo de Regressão Logística
Inicialmente será utilizado a Regressão Logística para criação do modelo, uma técnica mais tradicional que permite prever o resultado e possui alta explicabilidade em relação a outras técnicas.
Na próxima etapa será também construído outro modelo com uma visão diferente.
A utilização do algoritmo de Regressão Logística permite entender e explicar porque o score subiu ou desceu e ter uma visão mais clara sobre quais variáveis impactaram no resultado.
Todo o modelo foi construído pensando em otimização orientada pelo case, estamos no caso usando o ROC-AUC.
Durante a construção também serão feitos ajustes, já que a regressão logística trabalha melhor com um número reduzido de variáveis, para esse processo definiremos em torno de 25. Então serão escolhidas as melhores utilizando as técnicas necessárias para seleção.
Detalhes sobre a construção do Modelo de Regressão Logística
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/11_modelo_regressao_logistica.ipynb
Como base para iniciar a construção do modelo primeiro preparei o ambiente para desenvolvimento onde foram instalados as dependências, como o ambiente para esse projeto está sendo utilizado o Google Colab foram instalados as bibliotecas category_encoders e catboost.
Além da conexão do Google Drive onde os dados que serão utilizados estão. Também defini variáveis onde informam o local dos dados tanto para uso Local ou Online(Colab).
Foi importado uma lista de bibliotecas (nem todas precisam ser utilizadas inicialmente, algumas são para testes durante o processo) com os recursos uteis para criação do nosso modelo.
Leitura dos Dados
Como primeira etapa de mão na massa é fazer a leitura dos dados para treino que foram gerados na etapa anterior de Feature Selection.
Lembrando que é fundamental executar corretamente a etapa de seleção de variáveis para que no momento de construção do modelo você tenha dados de qualidade.
Funções auxiliares para trabalhar com o modelo
As funções visam facilitar todo o trabalho e gerar agilidade durante o processo, além da redução de código.
– Função Cálculo das Métricas – calculate_metrics
Essa função faz as predições e gera as métricas para o conjunto (de treino e teste) junto com as principais métricas (Acuracia, Precision, Recall, ROC-AUC, Gini e KS) do dataframe.
– Função para geração de Metadados do Conjunto de Dados – generate_metadata
Essa função gera os metadados, informações utilizadas na fase de categorização (categoriza as variáveis que não apresentaram comportamento linear com a log da odds)
Etapa de Split dos Dados
Etapa de extrema importância, visto que é fundamental fazer o split dos dados antes de qualquer coisa. Isso ajuda a evitar o Data Leakage.
Aqui removemos o TARGET e o ID visto que essas informações não serão utilizadas no treino e para evitar overfitting durante o processo. Separamos também 20% dos dados para teste.
Preparação dos Dados e Seleção de Variáveis para o Modelo
No Modelo Baseline foi utilizado Pipeline para organização e execução das etapas.
Aqui foi feito diferente porém seguindo a mesma lógica mantendo a estrutura do processo.
Na preparação dos dados foi feita:
- Imputação da média para as variáveis numéricas;
- Imputação do valor mais frequente para as variáveis categóricas;
- Foi aplicado essa mudança nas bases de treino e teste;
- Foi aplicado o TargetEncoder, porém poderia utilizar outra técnica.
Para seleção de variáveis foi definido o limite. Onde verificou-se a correlação e removeu variáveis acima de 0.5 (limite definido).
Até esse ponto foi a etapa mais manual do processo onde você pode ajustar para obter resultados diferentes e que podem influenciar nas etapas futuras.
Seleção de Variáveis com XGBoost
Foi utilizado o algoritmo XGBoost para realizar a seleção de variáveis para o modelo.
Pensando na regressão logística definiu se as 20 features mais importantes para o modelo.
Aqui pode ajustar e testar com mais ou menos para ver como se comporta o modelo e as métricas geradas, mas evite uma grande quantidade.
Também tome cuidado ao reduzir muito para que o modelo não perca o poder preditivo sobre os dados com a falta de informação.
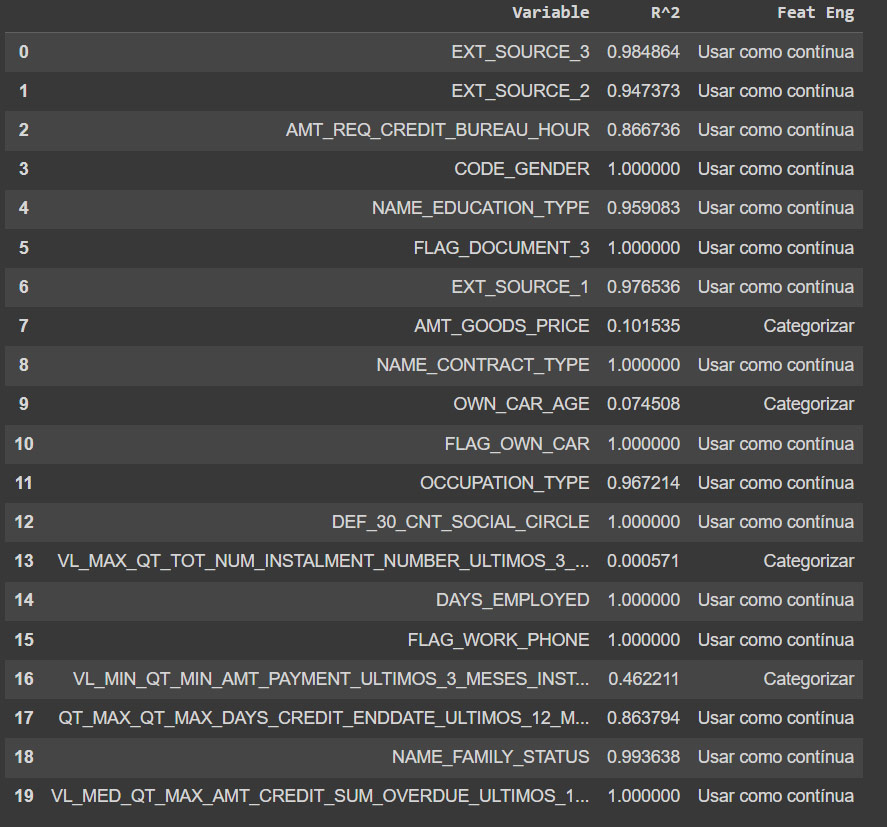
Ao final podemos ver como ficou a nossa ABT (Analytical Base Table) que contém é o conjunto de variáveis que poderão ser utilizadas pelo modelo.
Iniciamos o processo de Fature Selection com o total de 7852 variáveis e terminamos ele com 134 variáveis.
Agora com aplicação do algoritmo XGBoost refinamos mais chegando a 20 mais o TARGET.
Verificação da Linearidade com a Log da Odds
Para realizar esse processo devido a quantidade de variáveis foi utilizado uma função para facilitar. Ela recebe os dados, as variáveis e o TARGET.
Aqui verificamos através da função a linearidade da variável onde o R^2 mais próximo do valor 1 é melhor, já que apresenta um comportamento linear.
Para facilitar a interpretação temos o valor e o gráfico para analisar.
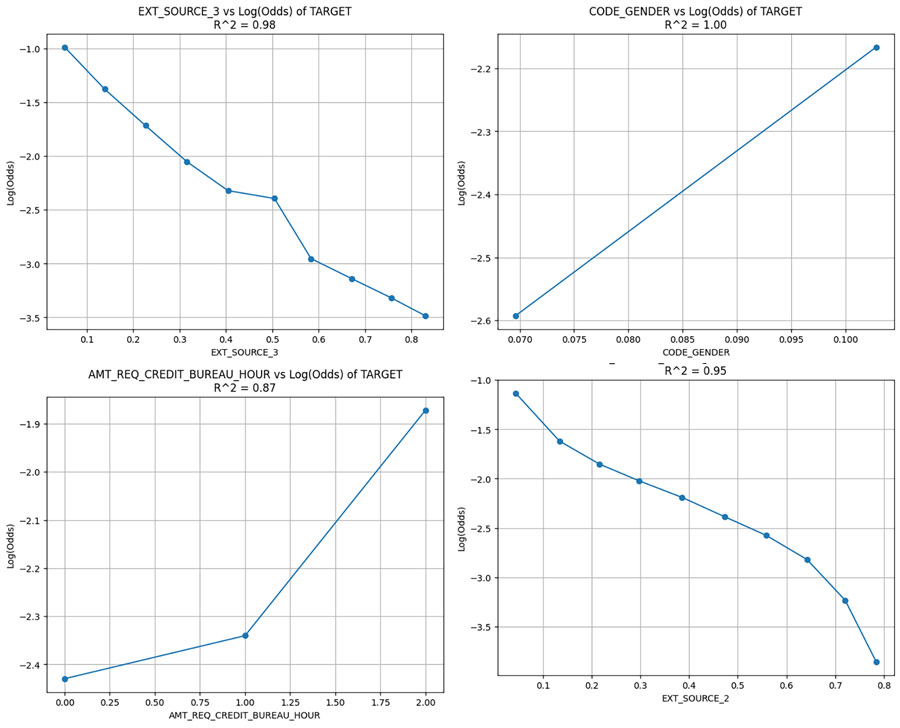
Depois de analisar as informações podemos definir através da função e um mínimo para R^2 para selecionar a variável e definir se é variável para uso como contínua ou se precisa categorizar.
O resultado disso é um dataframe com as variáveis, o R^2 e a engenharia de recursos para tomar a ação, tornando tudo muito visual e fácil de analisar.
Nesse ponto é importante testar e definir o limite aceitável do mínimo para R^2.
Esse processo separa as variáveis continuas das que precisam categorizar.
Transformação matemática
Com as variáveis para categorizar separadas, é hora de aplicar uma transformação matemática, podem ser feitas várias transformações.
Após isso é verificar a linearidade das variáveis após a transformação.
Uma vez feito o processo pode ser aplicado a transformação (tanto na base de treino como de teste).
Aplicação das transformações geradas
Após aplicar as transformações é gerado um novo dataframe.
Onde pode se verificar a ordenação das variáveis, se estão tendo ordenação.
- Checar se o comportamento é monotônico e não varia;
- Se estiver descendo deve permanecer sempre descendo;
- Se estiver subindo deve permanecer sempre subindo;
- É necessário garantir uma ordenação;
- Verificar a linearidade das variáveis, caso contrário trará problemas para o modelo gerado.
Tratamento de variáveis para transformar em categorias
Nessa etapa foi utilizado a arvore de decisão:
- Foi feito o agrupamento em taxa de maus, sempre olhando para o TARGET;
- A etapa de categorização é mais manual, onde a transformação é controlada pelo número de categorias desejado;
- O processo é sempre aplicado na base de Treino e Teste;
Depois foi ajustado os tipos de variáveis para OneHot Enconding.
No processo de categorização por ser bem manual, você pode fazer em cada uma para ver o que acontece, analisar o comportamento. E sempre fique atento a sua ordenação.
Evite gerar muitas categorias em variáveis que não tem a capacidade para não gerar erro. Cada variável tem um número ideal para se trabalhar.
Importante:
Quando falamos de regressão logística, além da Log da Odds e ordenação entre categorias. É muito importante checar a linearidade ao longo do tempo e ver se as linhas se cruzam.
Caso isso aconteça é recomendado agrupar as variáveis e transformar em uma nova. Sempre repetindo o processo.
No caso o dataset utilizado possui uma limitação e não é possível analisar a estabilidade ao longo do tempo.
Porém sempre que tiver os dados em safra avalie o comportamento:
- No treino;
- No teste (Out of Sample);
- Out of Time (aspecto temporal dos dados).
Tudo isso para garantir a qualidade do modelo.
Veja que até aqui o grande trabalho foi preparar e selecionar as melhores variáveis par o modelo.
Isso é muito importante já que são elas que irão influenciar no resultado, caso não cuide dessa etapa poderá ter um resultado ruim.
Criação do Modelo de regressão logística com as variáveis selecionadas
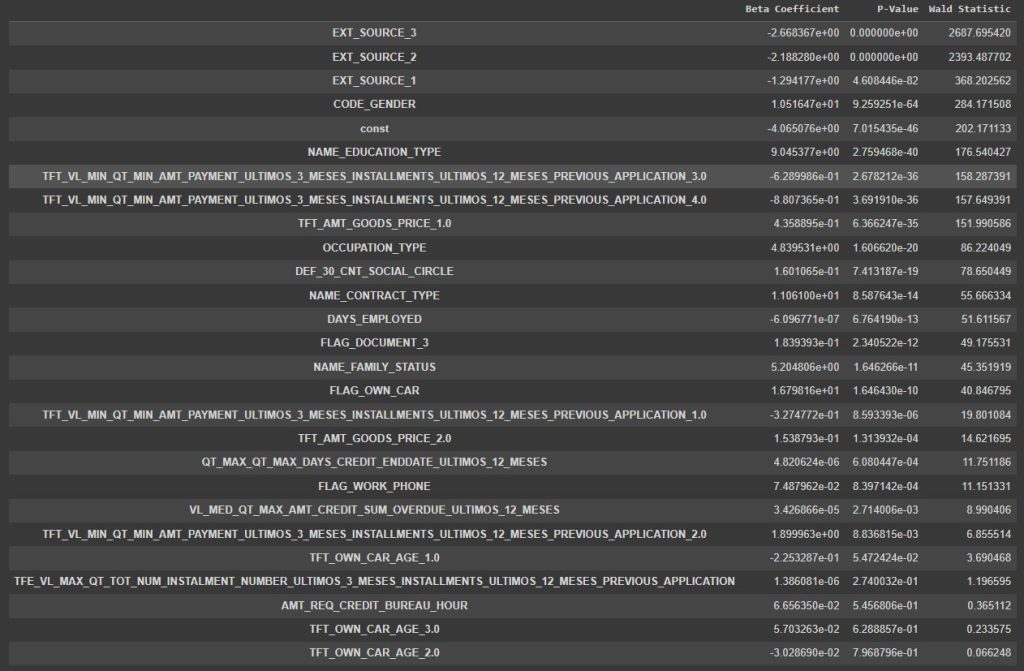
Para criação foi utilizado a biblioteca StatsModels pela sua facilidade na geração de informações como:
- Disponibilizar o P-Value
- Onde o valor precisa ser abaixo de 0,05 caso contrário é necessário rever a variável
- Statistic de Wald
- Quanto maior o valor, melhor para o modelo
- Ele é usado para analisar a significância
- Beta dos Coeficientes
- Relacionado a variável
Score Card:
Outro requisito do caso, onde aqui é gerado a relação das variáveis que entraram no modelo com o P-Value, Wald e Beta, e permite saber como isso impacta no Score (subir ou descer).
Importante:
Ao analisar o P-Value e remover as variáveis abaixo de 0,05 é necessário treinar novamente o modelo, e isso gera um novo Score Card onde altera o comportamento das variáveis. Já que força o modelo a redistribuir a importância entre elas.
É sempre importante testar pois pode gerar perda desempenho também.
Encerramos o modelo com a exportação do modelo para PKL (pickle) para ser utilizado.
Uso do Modelo
Até aqui foi feita toda parte técnica do modelo, onde foi criado o modelo de regressão logística, gerar o Score (tabela) para uso.
E se calculou as métricas para novo modelo tanto treino como no teste.
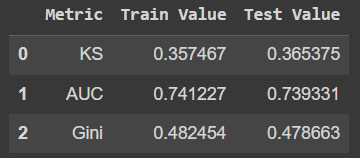
Verificou-se também a ordenação por decil e as métricas principais como KS, ROC-AUC e GINI.
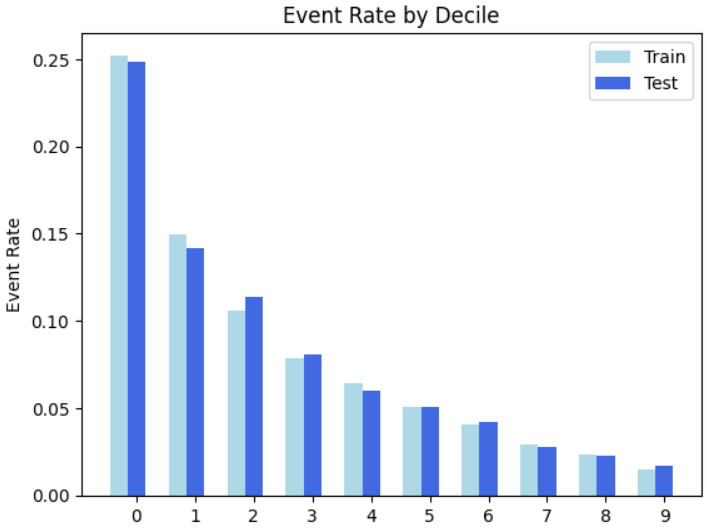
O que buscamos no modelo é a ordenação dos maus mais concentrado nos score da primeira faixa.
Essa concentração evita perder bons pagadores. Já que a boa separação é boa para os negócios e reduz o impacto.
Mas tenha em mente que quando a pessoa contrata e não honra é prejuízo para a instituição e isso pode acontecer mesmo nas outras faixas. Nunca teremos 100% dos maus que seria o ideal.
Sempre tem resíduos de maus nos outros scores. O bom modelo vai ter uma boa ordenação, concentração e boas métricas.
Sempre é importante olhar para o negócio buscando:
- Aumentar a aprovação
- Reduzir os riscos
Aqui criei o modelo de regressão logística que é conhecido pela sua estabilidade, e podemos ver isso através das métricas de treino e teste que estão próximas.
Regressão Logística Não é o Modelo definitivo
Esse embora seja um modelo tradicional podendo também ser conservador, é sempre bom conhecer outros e ter alternativas.
Nessa situação é possível ter o modelo que pensa em todas as preocupações com boa explicabilidade e também ter o modelo que pensa em performance e boas métricas visando maiores resultados.
Modelos Treinados e escolha do modelo desafiante: Técnicas avançadas de Machine Learning
Após criar o modelo de regressão logística, agora utilizei recursos mais avançados como treinamento de mais de um modelo, biblioteca Optuna para otimização de hiperparâmetros.
A utilização de algoritmos mais robustos pode trazer maior performance para o modelo e melhorias no resultado final, porém tem perda no que diz respeito a explicabilidade do modelo.
Portanto tudo deve ser analisado de acordo com o resultado que deseja junto a área de negócios.
Nessa construção os objetivos foram os mesmos, a criação do modelo e geração do score card. O que mudou foram as técnicas utilizadas.
Detalhes sobre a construção do Modelo
Código Fonte: https://github.com/lacostamkt/projeto-de-analise-de-credito-modelo-application/blob/main/12_modelos_desafiante_treinados.ipynb
O processo para construção do modelo basicamente seguiu como:
Importação de bibliotecas essenciais para criação e testes
Foram importadas as principais bibliotecas com o adiciona do Optuna que será utilizada para tunagem dos hiperparâmetros.
Criação de funções auxiliares para facilitar o trabalho
As funções seguem a mesma ideia e estrutura do modelo anterior para serem utilizadas como facilitador.
Leitura dos dados de treino e teste e checagem visual
Utilização das bases gerados pela fase de feature selection. Onde tínhamos cerca de 7852 variáveis e chegamos a 134.
Preparação dos dados
Sempre importante ressaltar a importância de fazer o Split dos dados antes de dar qualquer andamento nessa etapa, isso garantirá a qualidade e evitará o Data Leakage.
Essa etapa é muito similar a anterior realizada na regressão logística.
Aqui é feita a preparação como imputação de dados nas variáveis categóricas e numéricas para que o modelo possa utilizar os dados.
Foi utilizado novamente o TargetEncoder para que os algoritmos possam trabalhar melhor com os dados.
Aqui utilizamos Pipeline para pré-processamento.
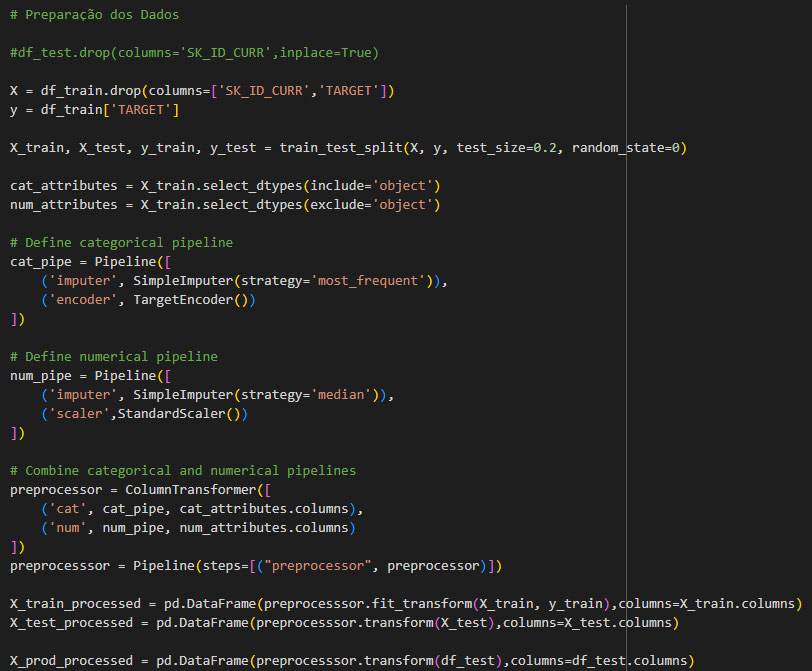
Nessa fase que o modelo se difere bastante da regressão logística, onde lá tínhamos uma seleção mais manual e artesanal das variáveis com checagem de algumas métricas como Log da Odds, R^2, análise da linearidade da variável e categorização.
Com esses outros modelos deixamos essa responsabilidade por selecionar as variáveis com eles.
O trabalho aqui é fazer uma boa configuração dos parâmetros e métricas que ele deve levar em consideração na hora de treinar e testar o modelo para que possa ser analisado.
Modelos utilizados no processo:
- DecisionTree
- LogisticRegression(SKLearn)
- RandomForest
- GradientBoosting
- XGBoosting
- LightGBM
Com a função para facilitar nosso trabalho é gerado uma tabela com as métricas dos modelos onde devemos olhar e analisar a que melhor se destacou e a partir dele fazer as otimizações nos hiperparâmetros. Lembrando sempre de se basear com o que foi pedido no case.
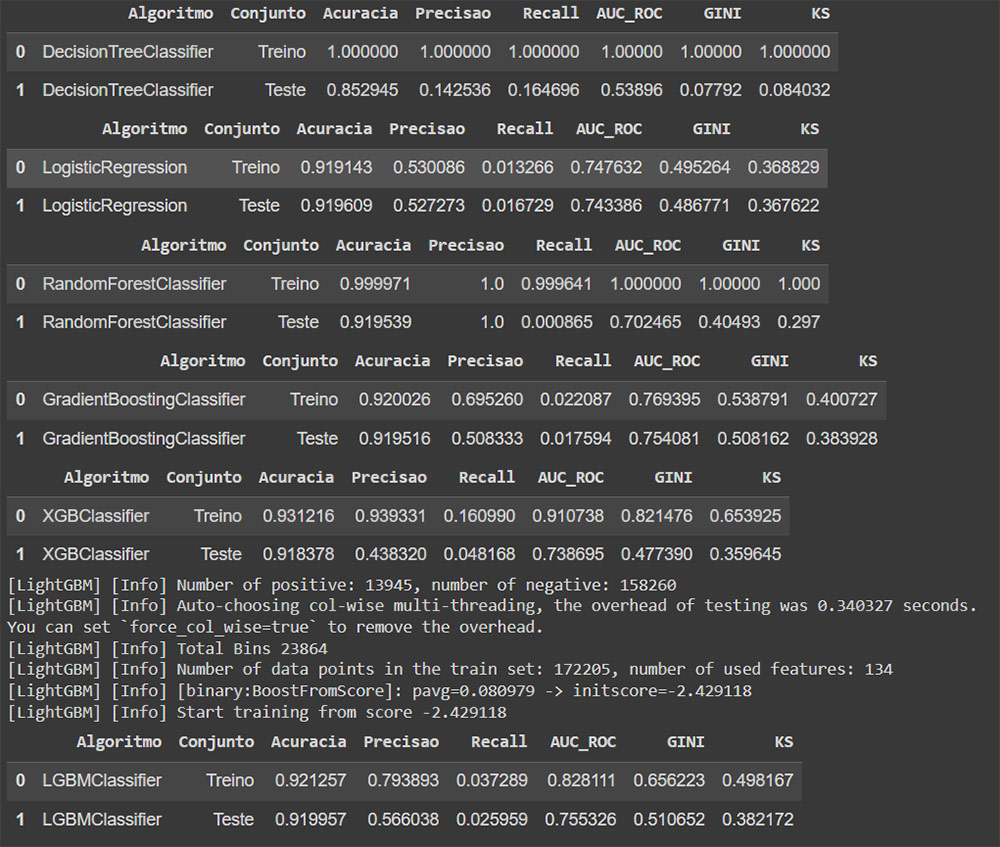
O modelo que mais se destacou com as métricas foi o LightGBM.
Veja que teve modelos que tiveram overfitting e necessitariam ser revistos, outros tiveram as métricas muito abaixo ou muito desbalanceada entre treino e teste.
O que buscamos aqui são boas métricas tanto no treino como no teste e com valores aceitáveis sem overfitting.
Importante:
Nesse dataset como já citado não tem dados para fazer o Out of Time que seria o ideal para checar a maturidade do modelo ao longo do tempo.
Ideias de Feature Engineering
Para enriquecer o modelo e tentar trazer melhorias para ele é possível combinar fatures e gerar novas a partir disso.
E para conseguir fazer isso é necessário entender mais sobre os conceitos de negócio e suas métricas e também fazer testes através de experimentações para checar em um ponto ideal.
Após essa etapa é novamente treinar o modelo nas bases de treino e teste para poder ter novas métricas e analisar os resultados.
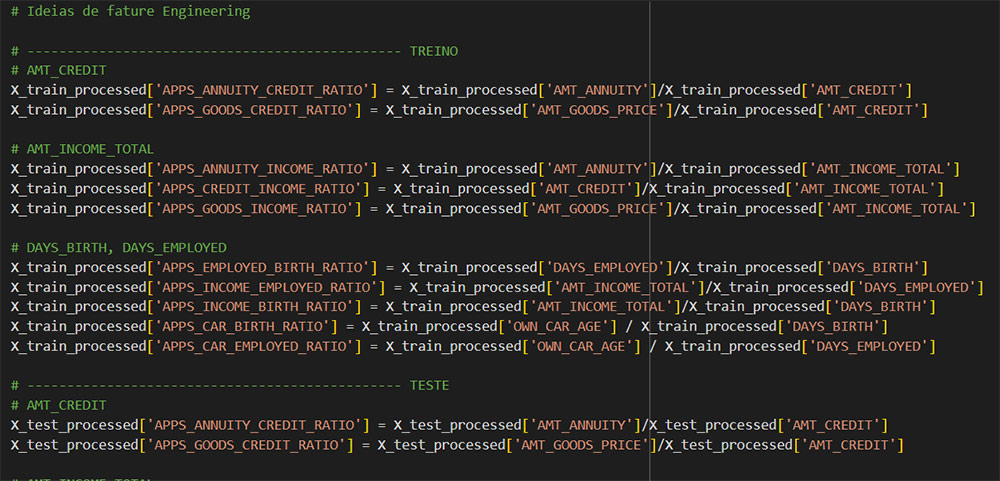
Hiperparâmetros: Otimização
Com o modelo que se destacou LightGBM, é feita a configuração para realizar a otimização.
Com os resultados obtidos foi feita a escolha do modelo e agora utilizado o Optuna para fazer as combinações e melhorias baseado na métrica ROC-AUC.
Na etapa de tunagem(otimização do modelo) é importante trabalhar com a validação cruzada para evitar problemas.
Sempre fique atento ao processo como por exemplo aplicar o TargetEncoder e aplicar o cross validation para garantir a qualidade do modelo. Utilize o treino e teste para comparar as métricas e assim se orientar.
Após a escolha dos parâmetros mais otimizados é feito o treinamento do modelo.

Seguindo ainda o case foi gerado a ordenação dos decis e o Score.
Todo o trabalho pode sempre ser feito comparando com os anteriores para poder acompanhar as melhorias nas métricas.
Aqui temos os resultados dos algoritmos prontos para serem confrontados e escolhido o melhor.
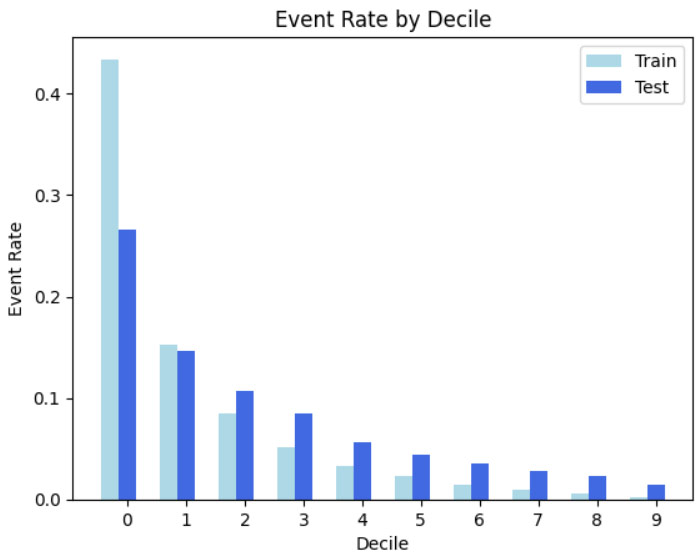
O que buscamos para o negócio é a maior concentração de maus pagadores nos decis iniciais, que é bom para o negócio. Através da ordenação é possível ver como está concentrado tanto no treino como no teste.
Escoragem
Após todo o processo já pode ser feito a escoragem com a base de teste para calcular os Scores e gerar o dataframe com os resultados.
Salvar modelo escolhido
Etapa final onde é salvo o modelo treinado para uso futuro.
A partir daqui é fazer a avaliação e se estiver satisfatório realizar a implantação.
Avaliação
Em construção.
Implantação
Em construção.
Dificuldades durante o projeto e Insights
Em construção.